| 前导 |
|---|
| 进程管理 |
| 内存管理 |
| 文件管理 |
引论
- 冯·诺依曼机:运算器、控制器、内存、输入设备、输出设备
- CPU:运算器 + 控制器
- 自顶向下看,操作系统为应用程序访问硬件提供了一层好的抽象
- 自底向上看,操作系统起到资源管理的作用
CPU、存储器、I/O 设备由一条系统总线连接起来,通过总线与其他设备通信。
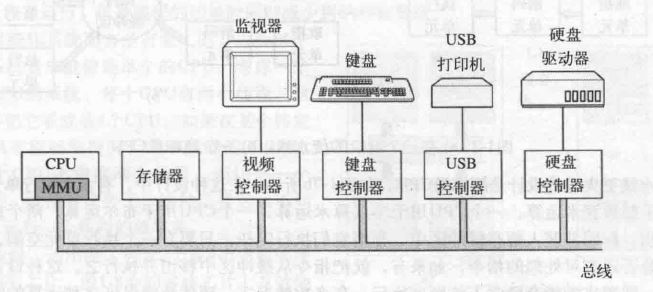
- CPU:取指、解码、执行
- 存储器:寄存器、高速缓存、主存(RAM)、磁盘
- RAM:Random Access Memory,随机访问存储器,断电即丢失内容
- ROM:Read Only Memory,只读存储器,非易失性(BIOS 存在这里)
- CMOS:计算机用以保持当前时间和日期,易失性
- I/O 设备在 UNIX 中作为特殊文件,像普通文件一样通过系统调用实现读写
系统调用:操作系统分为用户态和内核态,用户态里的进程需要通过系统调用的方式陷入内核执行相关操作,最后返回原进程
进程管理
程序(program)和进程(process):进程是程序的一次执行活动,必须要处理相应的数据,具有完整的生命周期。
- 一个进程就是一个正在执行程序的实例,包括程序计数器、寄存器和变量的当前值等
- 进程将存储空间划分为正文段、数据段(向上增长)、堆栈段(向下增长)
- 在 UNIX 中,只有一个系统调用
fork可以用来创建新进程- 进程是一棵树,UNIX 里所有进程均由一个祖先进程(
pid = 1)创建而来
- 进程是一棵树,UNIX 里所有进程均由一个祖先进程(
- 守护进程(daemon):空等待,请求来时被唤醒
- 僵尸态:已经结束的进程,还未清除管理数据(内存,文件等)
进程间通信方式
- 管道(pipes):传输字节流,单向
- 信号(signal):进程给进程发命令(整数),异步通信
- 2 SIGINT
- 9 SIGKILL(无法截断,收到就死)
- 共享内存
- 消息队列
进程调度
进程的三种状态:运行态、阻塞态、就绪态
- Running:正在运行(啥都有)
- Ready:可运行(除了CPU什么都不缺)
- Blocked:阻塞/睡眠(有别的条件未满足)
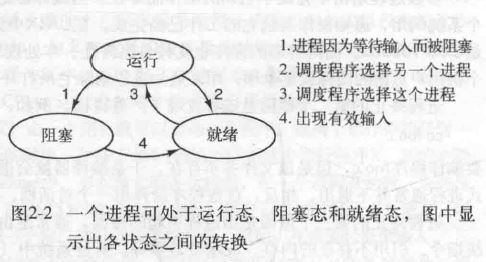
- 进程可以主动去睡觉(Running -> Blocked)
- 只有别的程序才能叫醒进程,未运行的进程不知道自己缺没缺东西
- 刚醒的进程只能进入就绪状态等待调度器(Blocked -> Ready)
调度器(Scheduler)处理运行态和就绪态间的切换,每个进程分时(timesharing)使用 CPU 实现伪并行;对不同系统下的不同进程,我们需要设计不同的调度算法来分配 CPU 的使用情况
- CPU 密集型进程(占据CPU多)
- 输入输出型进程(占据CPU少)
- 批处理系统:增大吞吐量,减小平均周转时间
- 吞吐量衡量批处理算法的性能,为单位时间处理任务的数量
- 交互式系统:响应时间合理
- 实时系统:有 deadline,需要精确响应
批处理系统调度算法
- 先来先服务(FCFS)
- 最短作业优先(SJF,先来的依旧会先处理,这里针对等待队列)
- 最短剩余时间优先
- 高响应比优先(HRF,等的时间长,执行时间短优先)
交互式系统调度算法(关心响应时间)
- 轮转调度(轮流使用 CPU,时间片为单位)
- 优先级调度(重点)
- 多级队列
- 最短进程优先
- 保证调度
- 彩票调度
- 公平分享调度
优先级调度算法:优先级最高的进程按照轮转算法分配时间片执行;优先级动态可变防止饥饿(低优先级的进程始终无法运行)。UNIX 示例如下:
- Priority : 0 ~ 127,0是最高优先级
- 实时(Realtime)进程:优先级固定,0 ~ 39
- 普通(Regular)进程:优先级是动态的
priority = base + nice + cpu_penalty- base 为预设值 40,保证实时进程始终优先于普通进程
- nice in 0 ~ 39,静态,越重要的进程 nice 越小,默认是 20
- cpu_penalty,动态,用 cpu 越多惩罚值越大,默认和使用时间片数目(cpu_usage)之比为 0.5,每秒钟会减半,针对 CPU 密集型进程
进程竞争
- 临界区(critical region):访问共享内存的程序代码
- 多个进程不能同时进入访问同一个临界资源的临界区
- 临界区之外的进程不能阻止其他进程进入临界区
- 互斥(Mutex):多个进程抢夺同一个临界资源产生竞争
- 协同(Synchronization):进程间具有协作关系,进程 B 需要等待 进程 A 处理完的数据
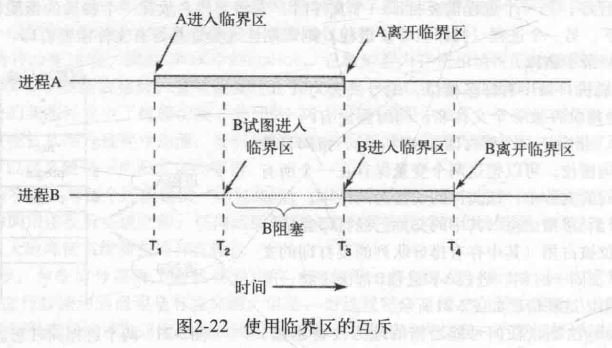
解决进程竞争问题的理论方法
- 屏蔽中断(大招,直接屏蔽所有中断,保证资源不共享)
- 锁变量(自旋锁 spin lock,本身也存在并发访问问题)
- 严格轮转法(用一个全局变量记录进程是否可以进入临界区,存在严重的等待问题)
- peterson 解法(维护一个 interested 数组记录临界区是否被进入,仅适用于两个进程)
- TSL (test and set lock) 指令,一般的操作系统中用
XCHG来原子性的实现取值并修改
1 | |
信号量(Semaphore)与 PV 原语
信号量由一个整数和等待队列(等待使用资源的进程)组成,每一个临界资源配备一个信号量,用于睡眠/唤醒/忙等待(忙等待不用进队列,轮询查看,多个进入忙等待的进程在有资源可用的时候并不明确是哪个进程会执行)。只能用 PV 原语对信号量进行操作。
- 睡眠/唤醒:整数范围是整个整数集,代表当前可用临界资源的数目;整数是负值表示当前资源均繁忙,并且等待队列中有进程正等待使用该资源
- 忙等待:整数范围是自然数,代表当前可用临界资源的数目;为 0 表示资源繁忙
- 注意和锁变量的区别,一般锁变量为 0 表示可用,1 表示被占用
- 记录型信号量:处理睡眠与唤醒,整数可以有负值,表示有几个进程在等待
- 非记录型信号量:处理忙等待,整数范围是自然数,最小是 0,代表当前可用临界资源的数目,无法知道有几个进程在等待
- 互斥信号量:只能取 0 或 1,忙等待的特殊形式
睡眠与唤醒的 PV 原语
1 | |
忙等待的 PV 原语
1 | |
经典 IPC 问题
生产者-消费者问题
1 | |
哲学家就餐问题(理解即可)
1 | |
数据库读写问题
读优先处理方案
1 | |
写优先处理方案
1 | |
公平读写
1 | |
还有一种高级同步原语叫管程。任意时刻管程中只能有一个活跃进程,由编译器负责检查。
进程与线程
一个进程中可以抽象出多个线程同时运行;线程间天然共享内存数据,每个线程拥有自己独立的栈和状态(切换上下文和恢复寄存器与进程相同)(!资源分配的最小单位仍然是进程,但线程可以成为调度的最小单位)
- 方案一:操作系统的内核维护进程表;进程内部的运行时(Run-time system)维护线程表;可以设定不同的调度算法
- 方案二:操作系统内核直接维护进程表和线程表,可以实现线程级别的阻塞(方案一线程阻塞会导致整个进程阻塞)
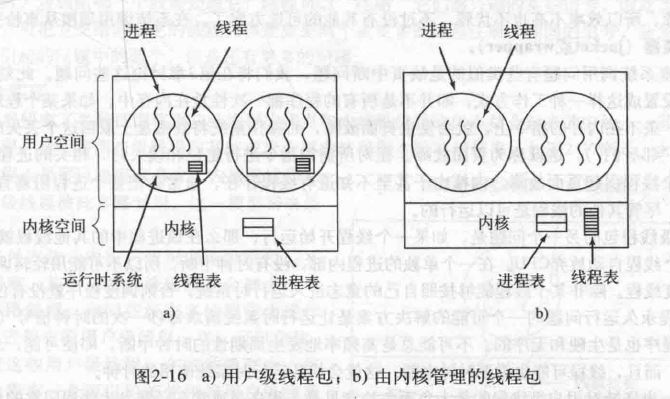
- 用户级调度快,且允许每个进程有自己定制的调度算法,但不好实现阻塞系统调用;同时在一个进程内部没有时钟中断,所以不可能用轮转调度的方式调度线程
- 内核管理的好处是所有能阻塞线程的调用都以系统调用的形式实现,缺点是开销代价大
死锁
死锁(一组进程互相等待)产生的条件
- Mutual exclusion condition(互斥)
- Hold and wait condition(部分拥有并期待更多资源)
- No preemption condition(不可抢夺)
- Circular wait condition(循环等待)
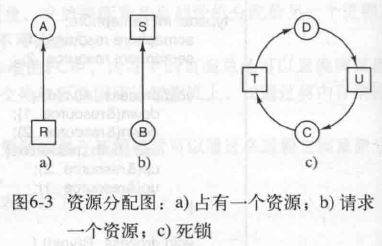
死锁的解决方案
- 鸵鸟算法(忽视,ignore)
- 检测与恢复(detection and recovery)
- 避免(avoidance),懦夫行为
- 预防(prevention),真的猛士!
死锁检测与恢复
处理方式:先杀死年轻的进程(资源是无穷的,图很难画出来)
- $(E_1, E_2,\dots, E_m)$:存在的资源,总数
- $C_{ij}$:进程 $i$ 占有的资源 $j$ 的个数(每行是一个进程)
- $(A_1, A_2,\dots, A_m)$:可用资源
- $E=A+C$
- $R_{ij}$:进程 $i$ 需要的资源 $j$ 的个数
一个死锁检测算法示例: $E=(4, 2, 3, 1)$, $A=(2, 1, 0, 0)$
\[C=\begin{bmatrix}0&0&1&0\\2&0&0&1\\0&1&2&0\end{bmatrix}, R=\begin{bmatrix}2&0&0&1 \\1&0&1&0\\2&1&0&0\end{bmatrix}\]- $P_3\longrightarrow A=(2, 2, 2, 0)$
- $P_2\longrightarrow A=(4, 2, 2, 1)$
- $P_1\longrightarrow A=(4, 2, 3, 1)$
死锁恢复方式
- 利用抢占恢复
- 利用回滚恢复
- 通过杀死进程恢复
死锁避免
进程运行完,占有资源会回收;按某种次序向进程分配可用资源直至进程运行完毕,若存在成功运行的序列,这个序列就叫做安全序列,存在的状态为安全状态,安全序列不唯一。
- 银行家算法(避免让系统进入不安全状态)
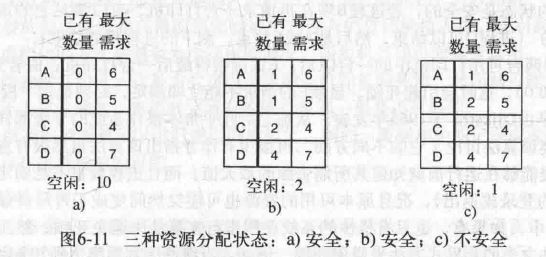
死锁预防
死锁的预防必然要破坏死锁形成条件中的某一条
- 互斥:spool everything(进入队列等待)
- 占有并等待:request all resources initially(所需资源一次全部 hold)
- 不可抢占:take resources away(我就抢!)
- 循环等待:order resources numerically(1, 8, 4, 9,请求 8 会检查你需不需要 4,需要会都给你,按需分配)
内存管理
把物理地址直接暴露给进程是很不现实的,因此引入了地址空间的概念来解决保护和重定位问题
- 分区:进程连续存放,不支持虚拟内存管理
- 动态重定位:将每个进程的地址空间映射到物理内存的不同部分
- 基址寄存器:装载程序的起始物理地址(相对地址 + 基址寄存器 = 绝对地址)
- 界限寄存器:装载程序的长度,防止越界
- 固定分区(开机时分配),内碎片,不可以被再次利用,最差分配无意义(内碎片要小)
- 可变分区,外碎片,可以被再次利用,最佳/差分配方法
- 分区的缺点是分配必须连续,需要内存紧缩(因为很难充分利用小碎片)
- 动态重定位:将每个进程的地址空间映射到物理内存的不同部分
在动态分配内存时,操作系统必须对其进行管理,可使用位图、链表(按照地址排序)进行存储管理
- 最佳适配:分配一个尽可能小的空闲区
- 最差适配:分配一个尽可能大的空闲区
进程地址空间不是一次性全部使用的,因此将地址空间划分为页,每次只 load 需要的部分即可,所以这些页在内存里可以是不连续分配的
内存超载的解决方案
- 交换(swapping):分区的交换,整个进程的进出
- Overlaying:不透明,程序员自己把程序分段,根据需要调度
- 虚拟内存
虚拟内存
从某个角度来讲,虚拟内存是对基址寄存器和界限寄存器的一种综合
- 分页(paging):可以实现虚拟内存,页表放在主存里
- 分页的最大作用在于:使得进程的物理地址空间可以是非连续的
- 物理内存被划分成一帧一帧,帧与页相对应
虚拟地址 $\rightarrow$ MMU(内存管理单元) $\rightarrow$ 物理地址
- 逻辑地址 = 页码 + 页偏移(只与页面大小有关)
- 物理地址 = 物理页号(页帧号) + 页偏移
- 页表项 = 标志位 + 页帧号
- 转换检测缓冲区 TLB(Translation Lookaside Buffer),也叫快表,相当于缓存
页表项标志位
- present/absent bit:表示该帧是否已经装载
- m:是否修改,修改了为脏页
- 文件型数据不确定,计算型数据一定是脏的
- r:最近有没有被用过位,定期清零
例:系统为 32 位实地址,采用 48 位虚拟地址,页面大小为 4 KB,页表项大小为 8 B
- 页偏移:12
- 虚拟地址页码:36
- 每个页可容纳 2^9 个页表项,四级页表
分页不会产生外碎片(内存都被划分为帧),可能会产生内碎片(帧内未利用空间)
- 页表项:页帧号 + 标识位;下标是页号,内容是页帧号
- 地址重定位:低 n 位页偏移,剩余部分为下标,与页表项匹配
- 多级页表:页表太大,把大页表拆成小页表,每个小页表的大小不超过页的大小
- 倒排页表记住概念即可,下标是页帧号,内容是页号,整个操作系统只有一张表;配合散列有奇效
页面置换算法
- OPT(最优页面置换):扔掉再也不用的页面/最长时间不需要访问的页(不可能实现)
- NRU(最近没使用的页面):顾名思义,r = 0;优先扔没用且干净的页(m = 0)
- FIFO:扔掉老的页面,用栈模拟
- Balady 异常:增加页帧数会导致缺页中断的增加
- Second Chance:扔掉老而没用的,给最老的页面第二次机会,如果 r 位为 1,说明你还有用,把你放在末尾(变年轻),r 位清零(第二轮一定能扔掉一个)
- Clock(时钟算法):同第二次机会,用环模拟栈,让指针指向最老的页面,指针会移动 如果老页面有用,指针向后移动
- LRU(最近最少使用):计数,扔掉最近最少使用的页,很难实现
- Simulating LRU(老化算法):老化即使用为在状态数组内一直右移;为每个页面维护一个 8 bit 的状态数组 x;每经过一个时钟,状态数组右移一位,将刚刚的 r 为放在数组首位;淘汰最小的数对应的页面
- 工作集置换:以时间为单位,将页面划分为等价的集合,一般来说同工作集的页面都被使用的概率比较大
- WSClock:指针时钟式轮询,不用淘汰的页面 R 位清零,这样总能找到可以淘汰的页面
- threshing:颠簸/抖动,A,B两个文件均需要使用,只有一个可使用页帧,来回被置换并没有执行逻辑的现象,解决这个现象的一个方法是始终预留一个半满的页面用于处理置换
分段
分段(段表):将地址划分为段,如符号表、源程序正文、语法分析书等;每个段都有自己独立的地址空间,会产生外部碎片。段表记录段的起点与长度,存在越界的可能;段比页要大得多,一个进程可能只有几个段。
分段的优点:
- 有逻辑性,按照用途划分段
- 只读共享(例如代码段)
- 保护
- 避免抖动(threshing)
分段页:先做段表,段指向页表(段内再分页),存储灵活,实现比较复杂
文件系统
文件是进程创建的信息逻辑单元,是对磁盘的建模,它提供了一种在磁盘上保存信息且方便读取的方法;可以把每个文件看成一个地址空间,进程可以读取已存在的文件,并在需要时建立新的文件。UNIX 和 Windows 均把文件看做无结构的字节序列,对操作系统来说它们就是简单的字节,其文件内容的任何含义只在用户程序中解释。
文件类型
- ordinary(普通文件)—— 狭义上的文件
- directory(目录)—— 文件夹
- special file(特殊文件)—— 硬件设备等(设备文件)
随机访问文件(random access file):UNIX 和 Windows 通过 seek 设置读取位置,在 seek 操作后从这个当前位置顺序开始读取文件
Inode
除文件名和数据外,所有的操作系统还会保存其他与文件相关的信息,如类型、大小、时间戳、保护位等,这些附加信息统称为文件属性/元数据(metadata),均存于 Inode。Inode 通过指针形成一了个树形结构与磁盘建立连接。
- Inode $\longrightarrow$ pointer $\longrightarrow$ datablock
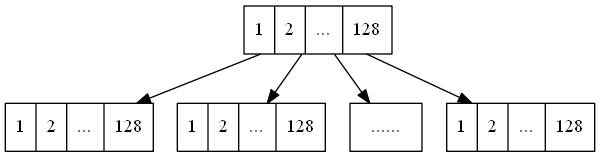
假设一个块大小为 1K,则一个指针块有 256 个指针,一级间接指针可访问 256K 大小的空间;二级间接指针可访问 256 * 256K = 64M 的空间;三级间接指针可访问 256 * 256 * 256K = 2^14M = 16G 的空间;如果将块大小扩展为4K,那么三级间接指针可访问 $(256\times4)^3\times4K=4T$ 的空间。
文件系统的实现
文件系统存放在磁盘上,多数磁盘划分为一个或多个区,每个分区中都可以有一个独立的文件系统
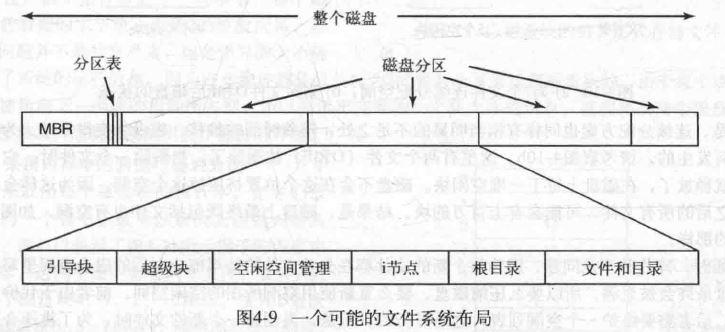
磁盘的 0 号扇区称为主引导记录(Master Boot Record),用来引导计算机,MBR 的结尾则是分区表
- 引导块:计算机被引导时,BIOS 读取并执行 MBR,确定活动分区后读入引导块;引导块中的程序将装载该分区中的操作系统
- 超级块:记录文件系统的关键参数,如块的数量等
- 空闲块:用位图/链表形式表示,顾名思义
- Inode:文件的基本属性
- 磁盘的其他部分存放了其他所有的目录和文件
文件存储的关键问题是记录各个文件分别用到哪些磁盘块
- 连续分配:顾名思义,删除文件会产生大量内部碎片,紧缩需要大量的计算
- 链表分配:顾名思义,随机访问会很慢(需要从头遍历查找)
- 采用内存中的表进行链表分配:取出磁盘块的指针字,把它们放在内存的一个表中,文件保存使用的磁盘块的链表(如文件使用了磁盘块 2, 7, 10, 4),这样一张表称为文件分配表(File Allocation Table),缺点是表占用内存过大
- Inode:树形索引
因此,几乎所有的文件系统都把文件分割成固定大小的块来存储以防止大量外碎的出现,使用位图/链表记录空闲块
如何提高文件系统性能
- 高速缓存
- 块提前读
- 减少磁盘臂运动:把有可能顺序访问的块放在一起,最好是在同一个柱面上
使用文件系统
- windows 盘符
- UNIX 装载 mount,将文件系统的根目录装载在其他目录上
- mount [what to mount] [where to mount],需要root权限;若原目录非空,则挂载后目录原有的内容被隐藏
虚拟文件系统(Virtual File System)将多种文件系统统一成一个有序的结构,即抽象出所有文件系统共有的部分,与上层用户进程交互;下层为不同的文件系统提供接口,这是 UNIX mount 实现的实际机制。
目录
文件系统通常会提供目录或文件夹以记录文件位置,在很多系统中目录本身也是文件。文件的文件名不存放于 Inode,而存在目录里;目录有自己的Inode和数据(数据为存储的文件名和其 Inode 编号)。
- 根目录 $\longrightarrow$ 子目录 $\dots\longrightarrow$ 文件
- . 当前目录; .. 父目录
可以实现一个文件有多个文件名,名字以链接 link 的形式存在,链接指向 Inode;一个文件有且仅有一个 Inode,Inode 决定文件是否相同,但不允许对目录做硬链接(防止成环);链接不允许跨越文件系统
- 链接 = 硬链接,link counter 记录硬链接的个数,删除其中一个硬链接文件并不影响其他有相同 Inode 号的文件
- 符号链接 = 软链接,以存放另一个文件的路径的形式存在,删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接就变成了死链接。符号链接并不是链接 link,软链接可以跨越文件系统
- 引入链接后,文件系统本身就成为了一个有向无环图(Directed Acyclic Graph)
用户、组与权限
- 用户与组是多对多关系
- 每个用户有且仅有一个主要组(primary group)
- 一个文件有且仅有一个主人(创建者),只可能属于一个组(创建者的主组);只有root可以修改主人和组两个属性
权限表示:rwxrwxrwx(owner, group, other),以二进制位呈现
- 普通文件
- r:可读
- w:可写
- x:可执行(只有可执行文件和脚本类文件可以执行)
- 目录
- r:可以进行 ls 操作
- w:可以进行增删文件操作(没有 x 则毫无意义)
- x:可以进行 cd 操作
sudo chmod 777,授予所有权限
| Command | Source directory | Source file | Target directory |
|---|---|---|---|
| cd | x | N/A | N/A |
| ls | x,r | N/A | N/A |
| mkdir,rmdir | x,w | N/A | N/A |
| cat, less | x | r | N/A |
| cp | x | r | x,w |
| cp -r | x,r | r | x,w |
| mv | x,w | None | x,w |
| vi | x,r | r,w | N/A |
| rm | x,w | None | N/A |
输入/输出
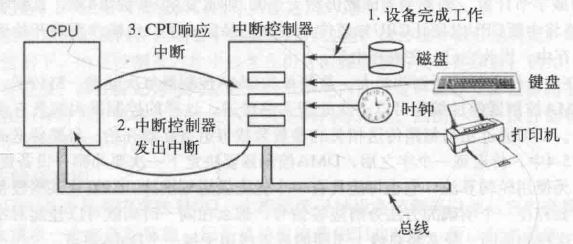
除了提供抽象以外,操作系统还要控制计算机所有的 I/O 设备;操作系统必须向设备发送命令,捕捉中断,并处理设备的各种错误。
- I/O 设备
- 块设备,如硬盘、光盘、USB,可寻址
- 字符设备,以字符为单位发送接收字符流,如打印机、鼠标,不可寻址
- 设备控制器:把串行的位流转换为字节块,并进行错误校正
- 设备驱动程序:具体控制 I/O 设备的代码
CPU 与 I/O 设备通信方式
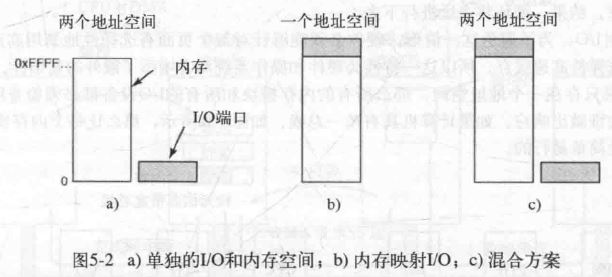
- I/O 端口空间:独立编址,使用专门的 I/O 端口和专门的 I/O 指令与内存通信
- 内存映射 I/O:统一编址,共用统一的地址空间,使用访问内存的方式访问外部设备
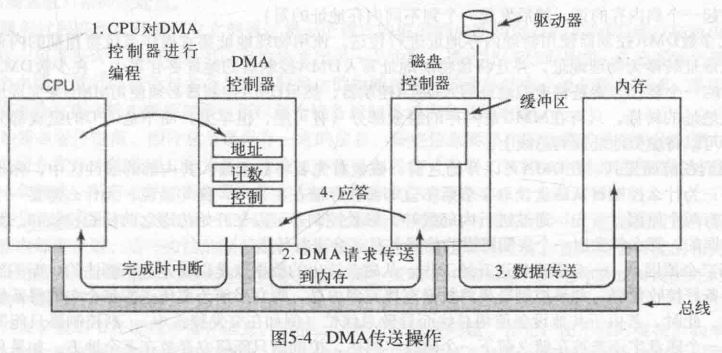
DMA
CPU 可以从 I/O 控制器中每次请求一个字节的数据,但是这样做浪费时间,所以通常会使用直接存储器存取(Direct Memory Access),DMA 独立于 CPU 并可以访问系统总线,由 DMA 代替 CPU 完成读取操作。
重温中断
盘
- 结构:磁头臂,盘片,磁道,扇区,柱面
- 柱面(cylinder)、磁头(head)、扇区(sector):CHS(三维坐标)、LBA(线性编址)定位具体扇区
- 扇区交错:便于读取(因为磁盘始终在旋转)
- 密度:建立映射,逻辑上各个磁道的扇区数相近
磁盘臂调度算法
磁盘存取:寻道 + 定位(算平均值) + 读取
- 先到先服务(FCFS)
- 最短寻道时间优先(SSTF)
- 电梯算法(SCAN):电梯折返commute,优先倾向于中间部位
- 优化电梯算法(C-SCAN):逻辑成环(起点是最小的磁道号!),折返的时候不响应中间请求
备份(backup)与恢复
- 给数据做冷备份(另存一份数据)
- 增量备份:全备份(level 0) $\longrightarrow$ 发生变化的部分备份
- 差异备份:全备份 $\longrightarrow$ 和全备份变化的部分备份
RAID
独立硬盘冗余阵列(磁盘阵列)
- RAID 0:多个磁盘并联(条带化),读写速度最快;其中任何一块硬盘损坏,则整个组就毁了
- RAID 1:两组以上的 N 个硬盘相互做镜像,可靠性最高
- RAID 1 + 0:RAID 0 的最低组合,将两组镜像并联,每组视为 RAID 1 运作;1 + 0要优于0 + 1
- RAID 0 + 1:与 1 + 0 相反,每组视为 RAID 0 运作
- RAID 5:条带化,算法(奇偶校验)备份分散在其他硬盘上,兼顾各方面,至少需要三块硬盘(通过算法恢复损坏数据)