| PAPER |
|---|
| Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks |
| The Close Relationship Between Contrastive Learning and Meta-Learning |
| MAML is a Noisy Contrastive Learner in Classification |
Introduction
Contrastive learning methods rely on applying different data augmentations to create different views of the same training sample. The key intuition behind contrastive learning is to keep the positive samples stay close and pull away the negative samples. Prevalent contrastive learning achitectures like SimCLR, BYOL always contain two parallel branches to create two augmented views of each data.
- Positive samples: different views of the same data
- Negative samples: views from the same augmentation of different data
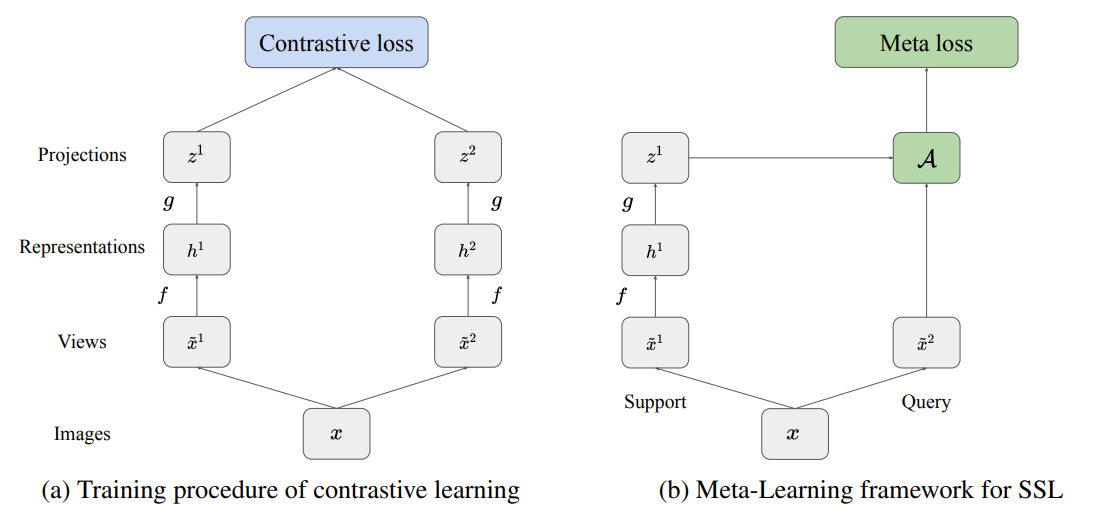
A classic meta-learning framework like MAML treats conventional supervised signal as the combination of different tasks. Each task contains corresponding support set and query set. MAML contains two important loops for updating the parameters of the model:
- Inner loop: update and save parameters in each step on given support sets
- Outer loop: sum over all losses on query set across all tasks and update parameters

For example, a few-shot classification problem refers to classifying samples from some classes (query data) after seeing a few examples per class (support data). In a meta-learning scenario, we consider a distribution of classification tasks, where each task is a few-shot classification problem and different tasks have different target classes. The widely accepted intuition behind MAML is that the models are encouraged to learn general-purpose representations which are are easily transfered to novel tasks. That’s similar to the aim of contrastive learning: to learn a good intermediate representation, which is beneficial to enhance the ability of domain adaptation.
Boost SSL with meta-specific augmentation
In contrastive learning or other SSL framework, we should create different views of each data where different data augmentations are conducted. Then we optimize the model through designed auxiliary tasks like discriminating different views of samples or predicting masked regions of the data. Assume that there are several augmentations we could apply. If we randomly sample a batch of augmentations to obtain views (support set) for optimization, which is similar to the inner loop in the meta-learning, we can update the base model parameters on query set after inner loop.

The figure above illustrates a meta-learning framework for SSL. In fact, data augmentations play an important role in contrastive learning and meta-learning when we carefully choose them. Large rotations, and other dramatic transformations actually decrease the performance when instead applied independently on support or query samples. This phenomenon also exists in traditional parallel contrastive learning framework like SimCLR and BYOL. By keeping images with very large augmentations in the same class, we may accidentally encourage models to learn overly strong invariances which do not naturally exist in the data. Thus, we need a meta-specific (task) augmentation, which aims to expand the number of classes available for sampling rather than expanding the number of samples per class. That is to say, we should treat each view after different large augmentations as a novel class.

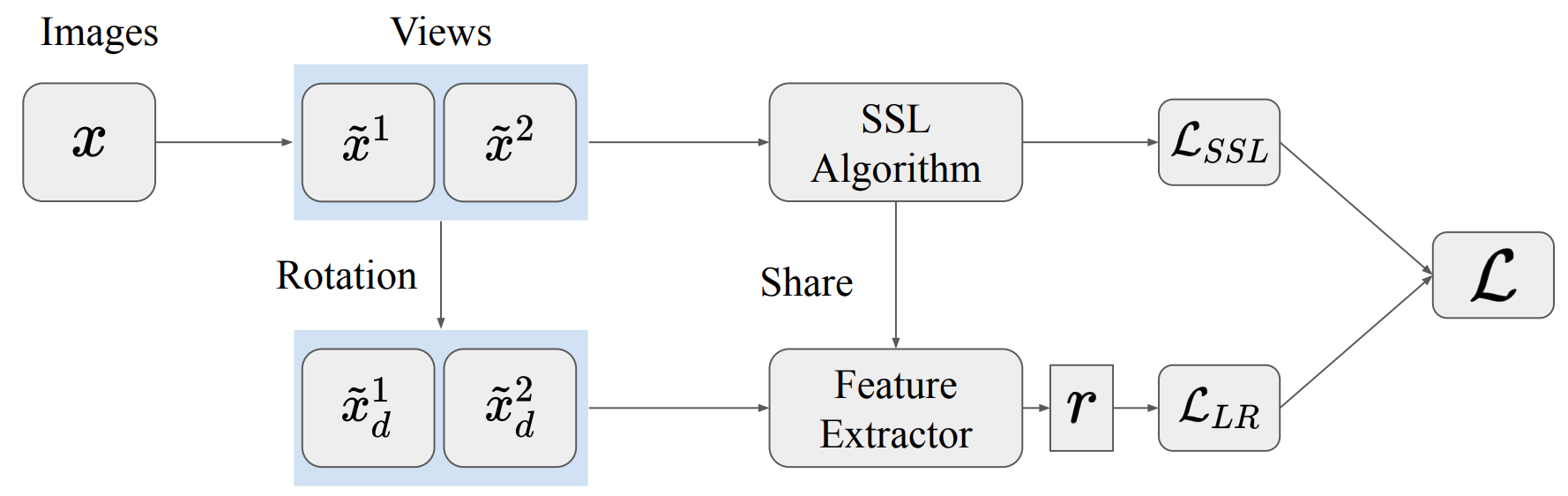
For a MetaContrastive learning framework, the model should discriminate not only different views from augmentation but also different transformations applied on the data or views. That is, different designed transformations applied on the same data may be a good choice for pseudo label.
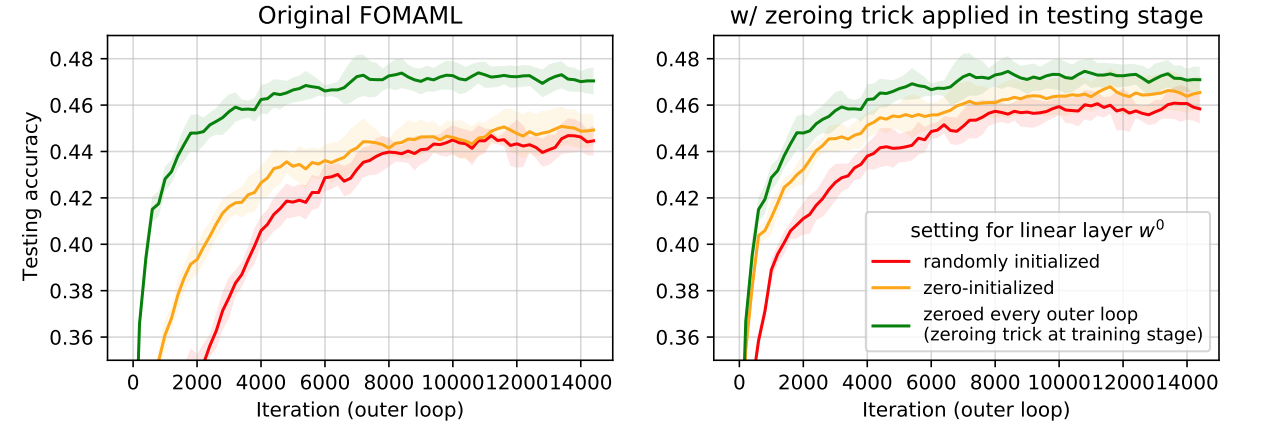
MAML is a noisy contrastive learning
Consider a 5-way 1-shot classification meta-learning scenario. We first update parameters of the model on given support sets and then fine-tune the model on the query set across tasks. This procedure actually could be seen as to reduce discrepancy between support and query set.
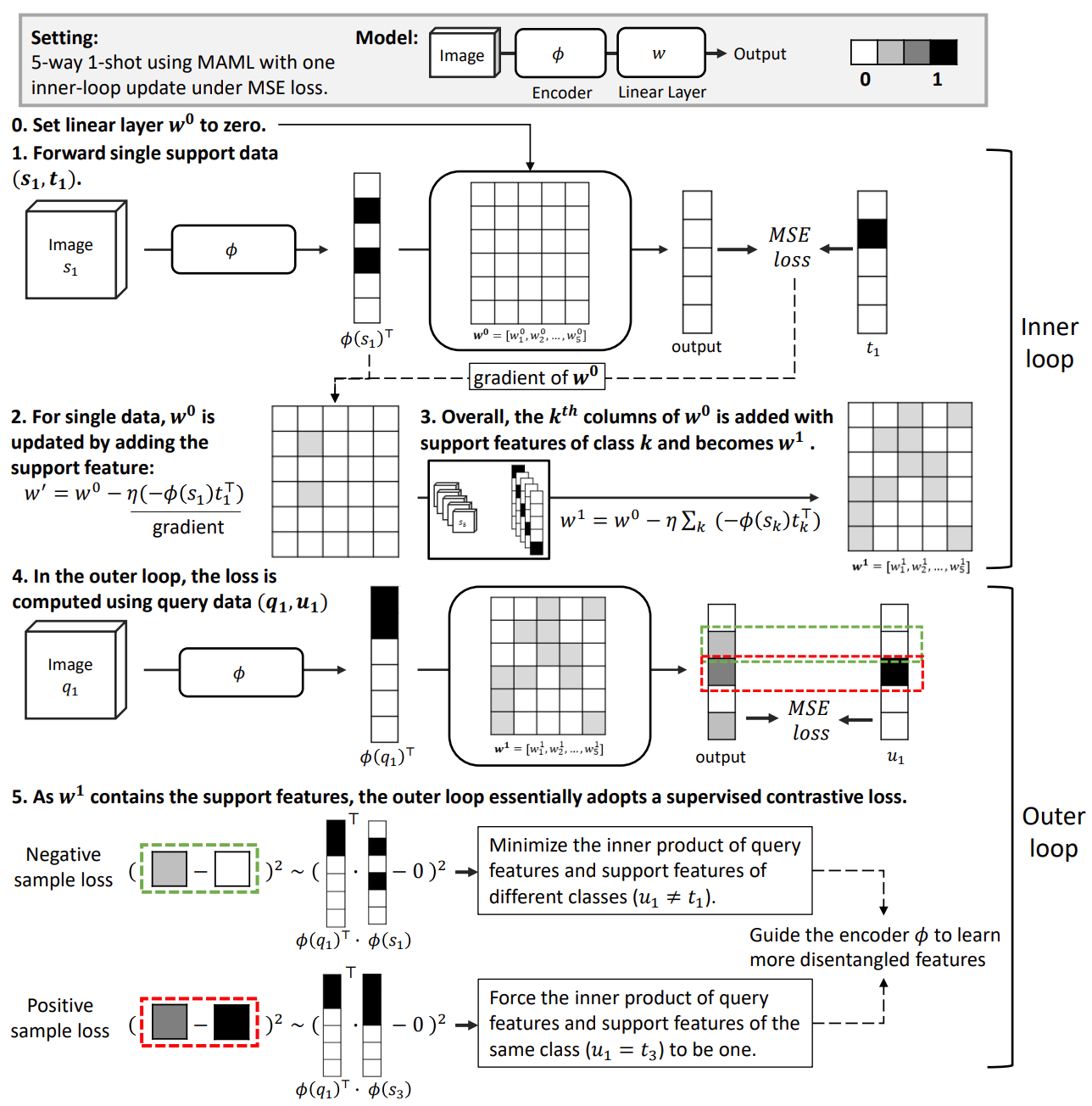
In figure above, we can see that in the outer loop of meta-learning, the MSE loss tries to minimize the similarity between the query features and the support features when they are from different classes, or force the inner product of the query features and the support features to be one when they have the same label. This is just a classic contrastive learning scheme, where the positive samples are similar support and query features and negative samples are dissimilar ones. Thus, we should carefully conduct parameter initialization.
In vanilla MAML, non-zero (random) initialization for the linear layer leads to a noisy contrastive learning objective. Just seting weights of linear layer to zero due to inner product, we can achieve a better performance of MAML. Surprisingly, with the zeroing trick, a larger number of inner loop update steps is not necessary! We should pay more attention to the mechanism of meta-learning and attach more importance to parameter initialization.