Motivations
Vanilla mixup directly interpolates raw input data and corresponding labels. Recent mixup methods mainly focus on three aspects to improve its performance:
- Raw input or Latent representation (manifold mixup)
- Adaptive region (SaliencyMix, FMix)
- SwitchOut or directly interpolation
However, these mixup images are overlays and tend to be unnatural. So what is a good interpolation of images? Back to SaliencyMix, which tries to combine two or more objects from different images into one in the input space, we can see that the foreground (object) is more important than background in one image. That is, if we can deform one object into another while maintaining the background, the model will learn more information about these objects from augmented data.

That is the core motivation of AlignMixup, deformation, where alignment should be concerned. AlignMixup aligns the feature tensors of two images, retaining the geometry or pose of the image where we keep the coordinates and the appearance or texture of the other. What we obtain is one object continuously morphing.
AlignMixup
Alignment refers to finding a geometric correspondence between image elements before interpolation. The feature tensor is ideal for this purpose, because its spatial resolution is low, reducing the optimization cost, and allows for semantic correspondence. Figure 2 demonstrates the procedure of AlignMixup.
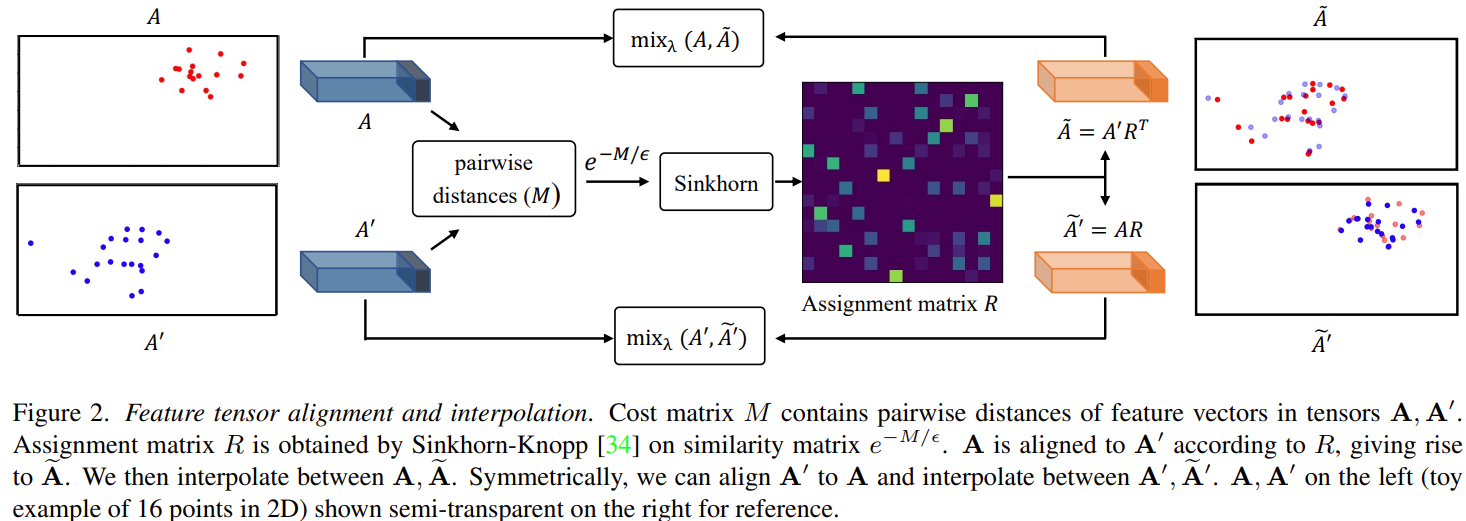
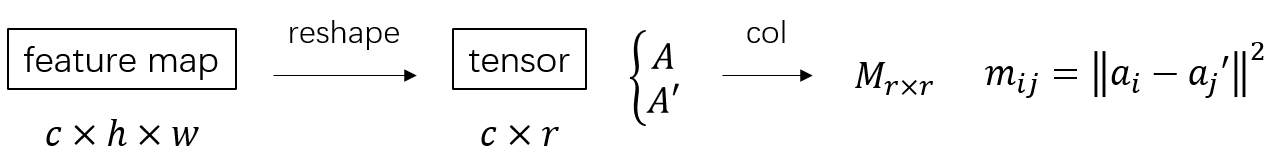
The columns of $A,A’$ describe the spatial information of images. $M$ formed with these columns measures the geometric correspondence of two images. Defining ${P\in\mathbb{R}^+_{r\times r}:PI=P^TI=I/r}$, we can get a optimal $P^*$ using Sinkhorn algorithm.
\[P^*=\arg\min\langle P,M\rangle-\epsilon H(P)\] \[R=rP^*\qquad\begin{cases} \tilde{A'}=AR \\ \tilde{A}=A'R^T \end{cases}\]$R$ is the final transformation matrix for alignment. $\tilde{A}$ means align $A$ to $A’$. The following image shows the result of mixed images with alignment or not.

By aligning $A$ to $A’$ and mixing them with small $\lambda$, the generated image retains the pose of $x$ and the texture of $x’$. Randomly sampling several values of $\lambda$ during training generates an abundance of samples, capturing texture from one image and the pose from another. Notice the autoencoder is trained using only clean images.
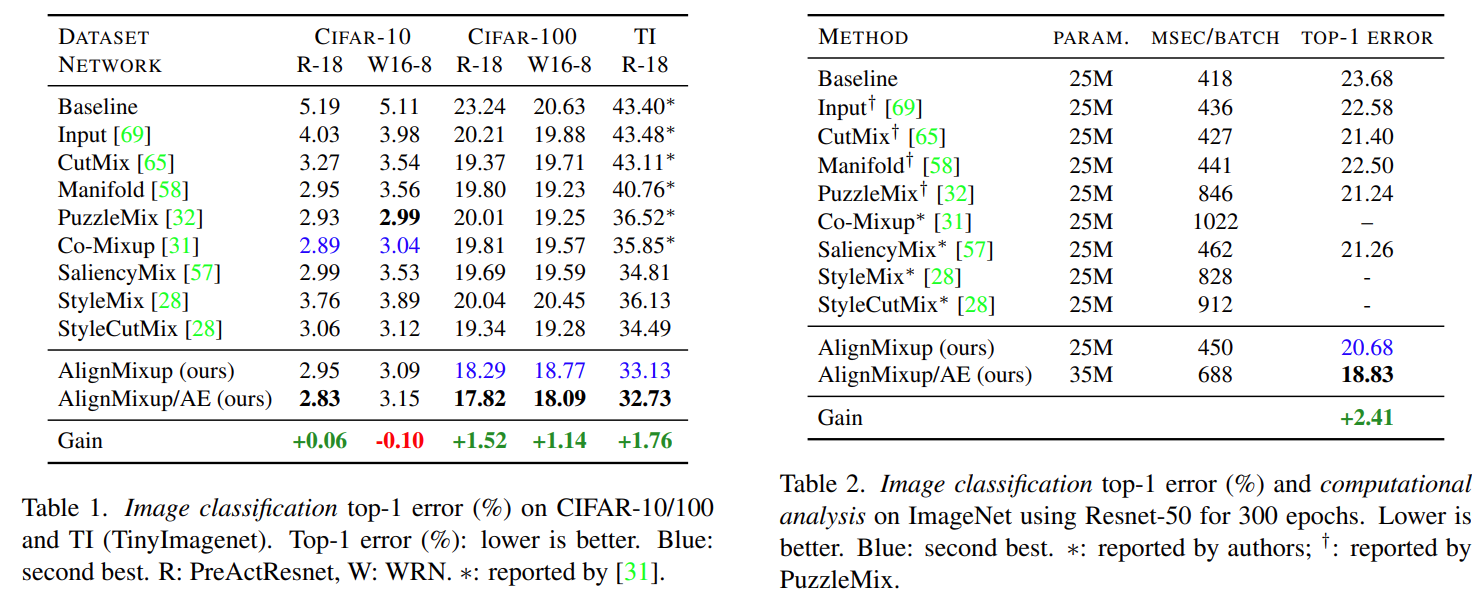
Some results are shown as tables below. AlignMixup performs well on image classification tasks. It also works on robustness to FGSM and PGD attacks, OOD (out of distribution) problem and weakly-supervised object localization and becomes a new SOTA mixup method. But we should emphasize that manifold mixup takes longer training time (2000 epochs) than methods which perform mixup in the image space (300 epochs). This remarkable phenomenon should be noticed.