Motivations
The Receptive Field size has been one of the most important factors for feature extraction in most tasks. In addition to the multi-scale feature extractors using the pyramid structure, recent work has begun to focus on adaptive or omni-scale receptive field.
In time series, we often use 1D-CNN or Transformer with sparse attention as feature extractor, where the receptive field is called time scales, warping size or window length. Although these researchers have searched for the best receptive field or just adopted pyramid feature extraction scheme, there are still two questions remained:
- What size of the receptive field is the best?
- How many different receptive fields should be used?
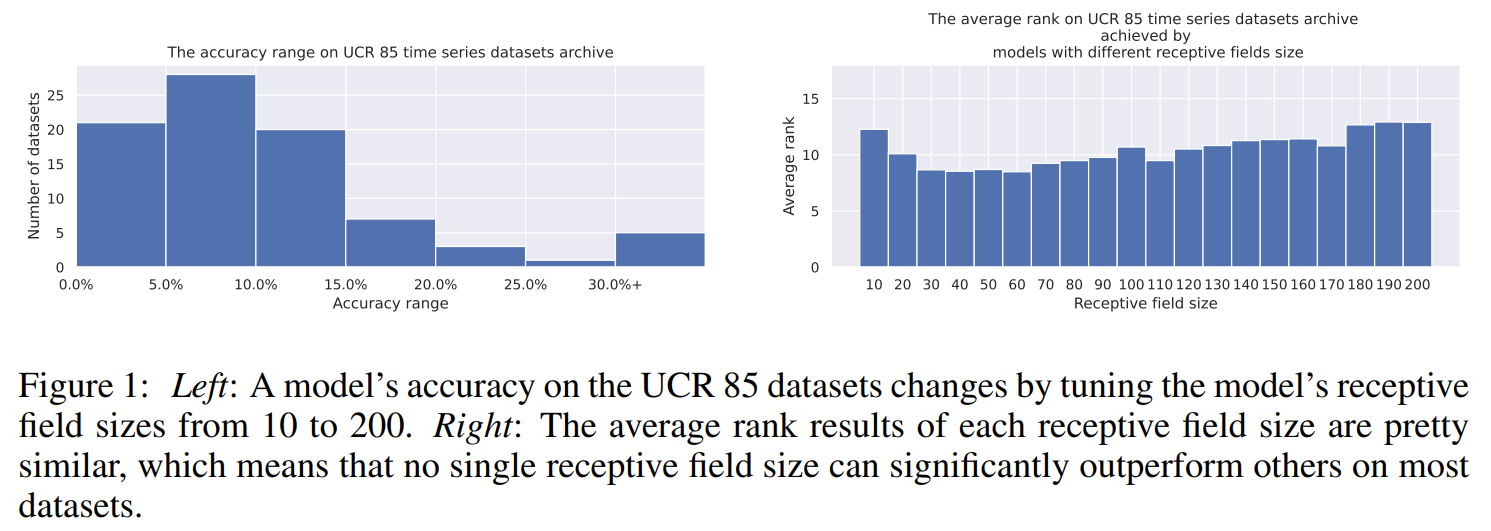
Experiments on UCR dataset show the effect of receptive field size on model’s performance. Moreover, no receptive field size can consistently perform the best over different datasets.
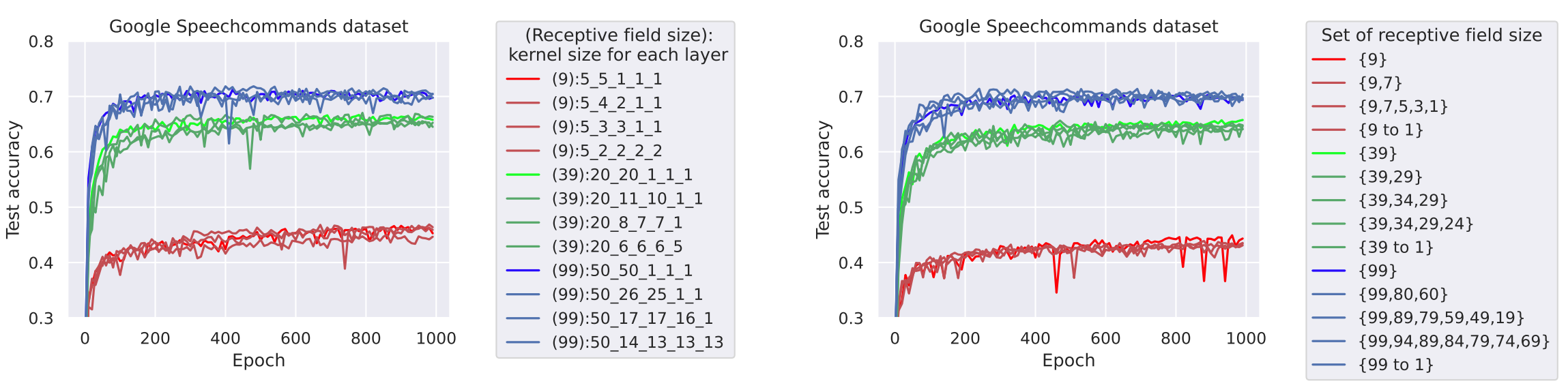
Experiments on Google Speechcommands dataset demonstrate that model’s performance is positive correlation with the receptive field size. The performance of 1D-CNNs (combination or multi-kernel) is mainly determined by the best receptive field size it has. That is, if the model can cover all receptive field sizes, its performance will be similar to a model with the best receptive field size.
Omni-scale 1D-CNN
According to Goldbach’s conjecture, any positive even number can be written as the sum of two prime numbers. OS-block uses a set of prime numbers as the kernel sizes except for the last layer whose kernel sizes are $1$ and $2$ (stride size is $1$).
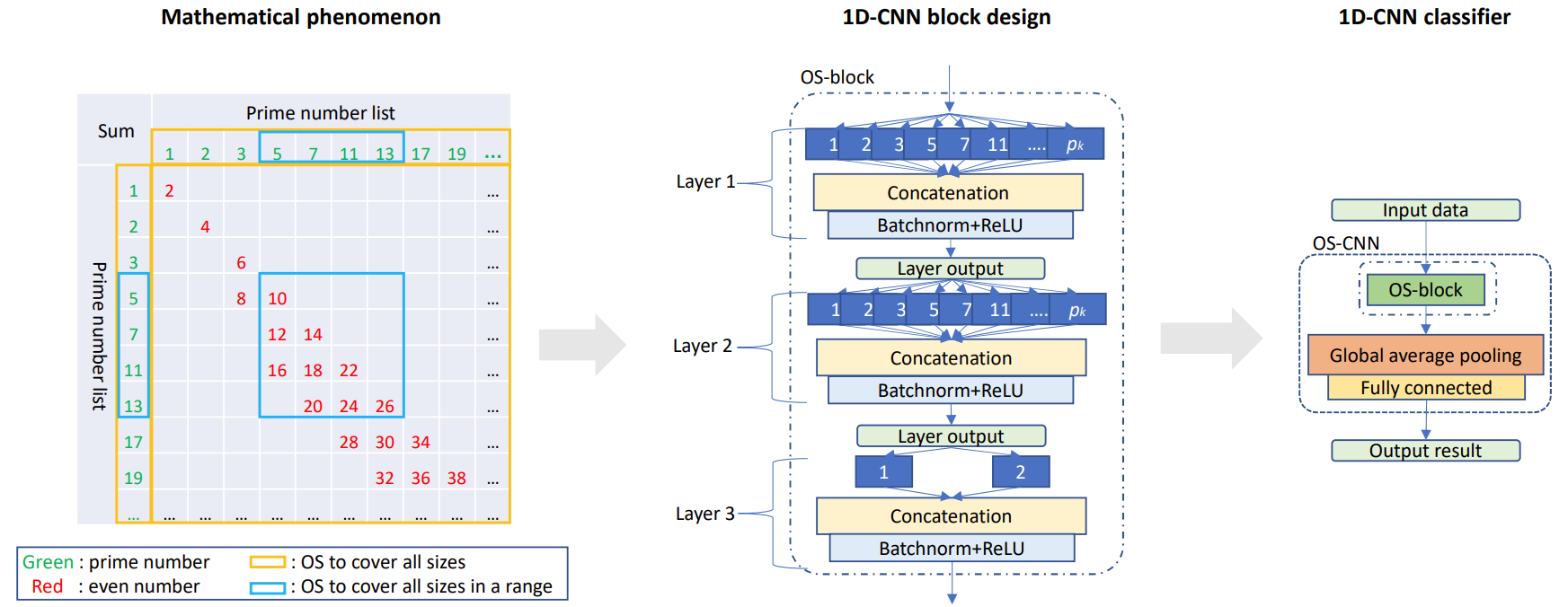
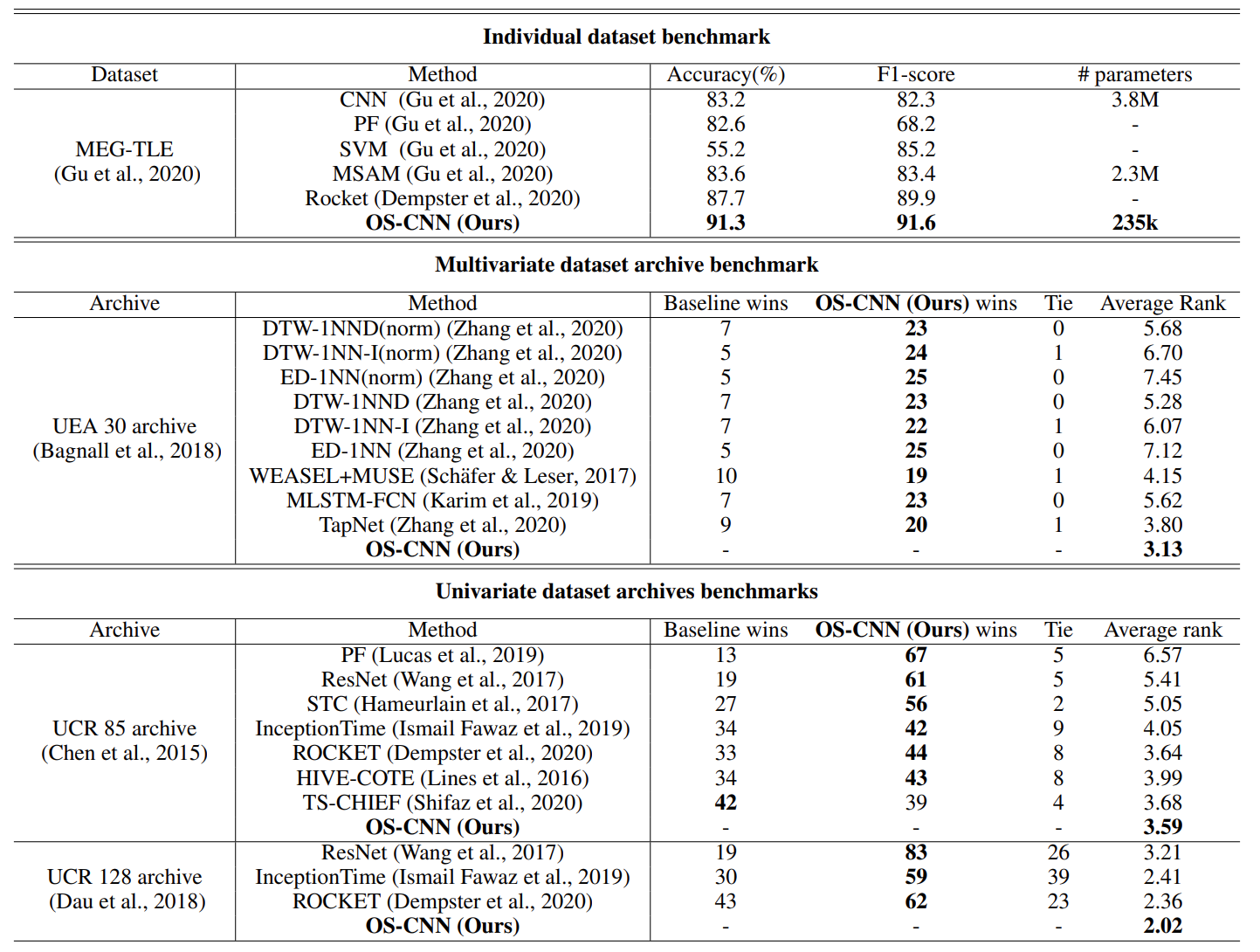
For most tasks which have to adopt multi-scale scheme, we can directly add OS-block into the feature extractor, or modify the architecture using similar strategy. Some results are shown below.
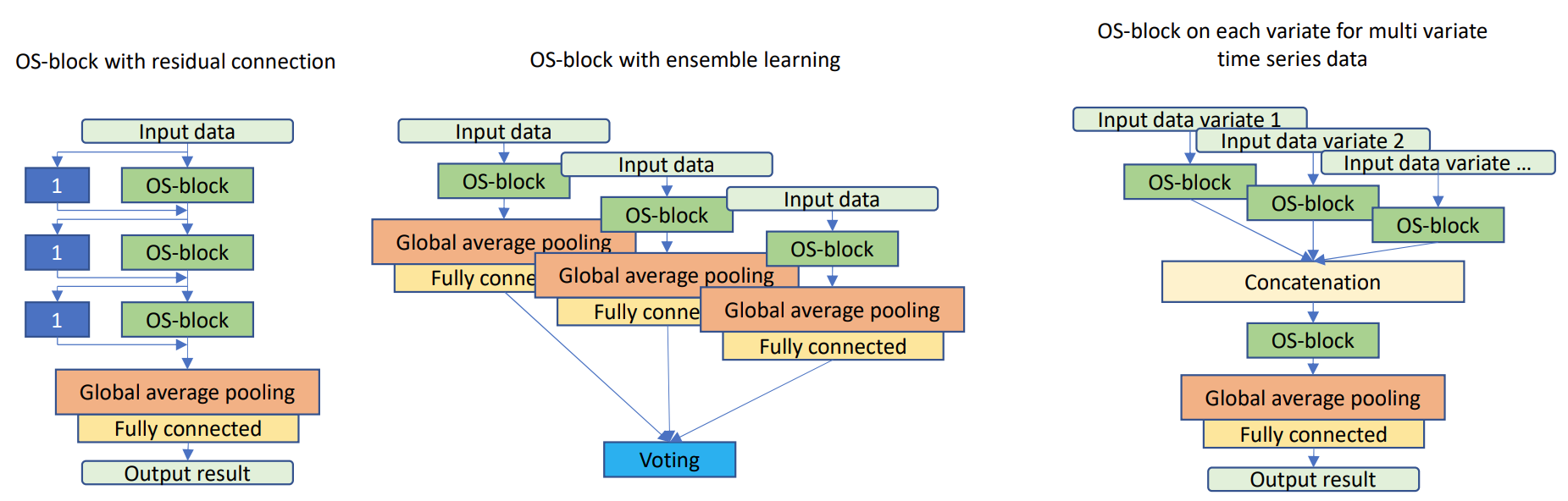
It should be notice that, there might be many options to cover all receptive field sizes. Is there a more efficient design? We should consider it and try to apply omni-scale receptive field to other models like sparse attention in Transformer.