| PAPER |
|---|
| Longformer: The Long-Document Transformer |
| Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context |
| Poolingformer: Long Document Modeling with Pooling Attention |
Motivations
Transformer-based models are unable to process long sequence due to their self-attention operation, which scales quadratically with the sequence length. Thus, most of existing transformer models set the maximum sequence length to 512, which often leads to a worse performance in long sequence tasks.
\[\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\]In previous work, there are three widely adopted approaches to mitigate this problem:
- Split long sequence into segments
- Approximate the dot product in self-attention such as random projection
- Sparse attention which focuses on making each token attend to less but more important context
LongFormer
Longformer’s attention mechanism is a combination of a windowed local-context self-attention and an end task motivated global attention that encodes inductive bias about the task.
Local attention induces each token to attend to neighboring tokens corresponding to local context.
- Sliding window attention
- Dilated sliding window (similar to dilated convolution)
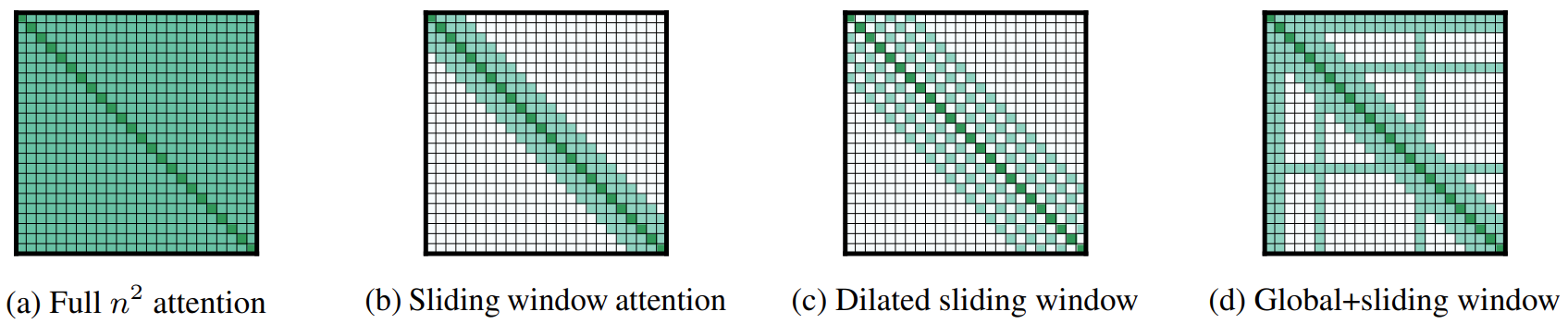
To get a task-specific representations, we need to find a token with a global attention attends to all tokens across the sequence, and all tokens in the sequence attend to it. For example, BERT aggregates the representation of the whole sequence into a special token [CLS]. In QA, global attention is provided on all question tokens.
LongFormer combines local and global attention to capture representation from long sequence with $\text{O}(n)$ complexity. In particular, they use small window sizes for the lower layers and increase window sizes as they move to higher layers. They do not use dilated sliding windows for lower layers to maximize their capacity to learn and utilize the immediate local context.
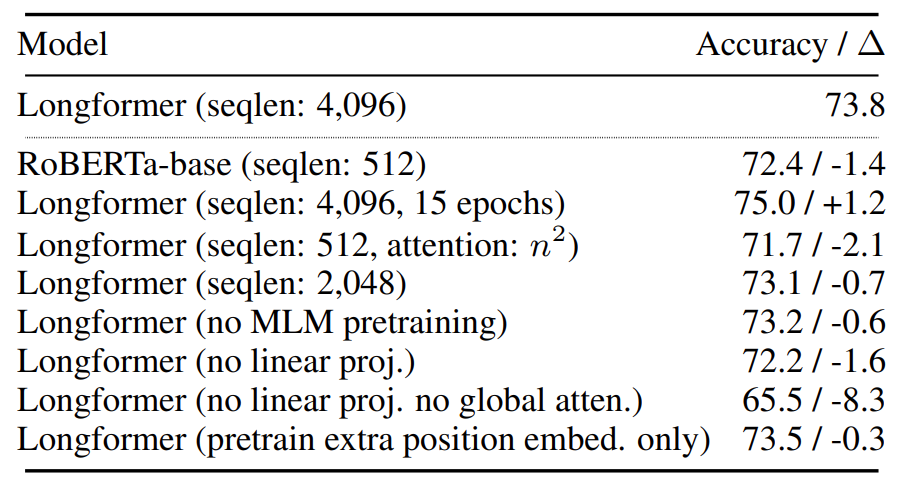
LongFormer adds extra position embeddings to support up to position 4096, coping from other pre-tranined models. We can see that LongFormer performs well on long sequence modeling. Performance drops slightly when using the RoBERTa model pretrained when only unfreezing the additional position embeddings.
In fact, it is hard to directly apply LongFormer on other types of long sequences such as time series due to the importance of global attention and position embeddings. Task-specific global attention will bring severe inductive bias which will cause domain shift problem in transfer learning.
Transformer-XL
Transformer-XL does not use sparse attention mechanism. It improves conventional approaches which split long sequence into segments by adding recurrence scheme (like residual connection).

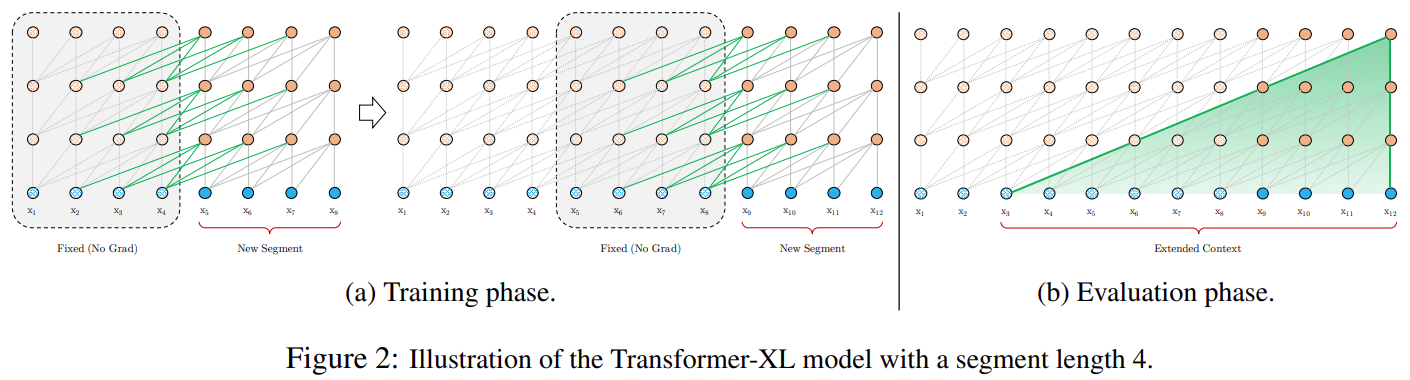
The hidden state sequence computed for the previous segment is fixed and cached to be reused as an extended context when the model processes the next new segment. Thus, the largest possible dependency length grows linearly with respect to the number of layers as well as the segment length because representations from the previous segments can be reused instead of being computed from scratch as in the case of the vanilla model.
To keep the positional information coherent when they reuse the states, Transformer-XL introduces relative positional encodings which are only concerned about relative distance of two positions. (i.e. temporal order or bias) Additionally, they propose a new metric RECL to measure the ability of capturing the long context dependency.
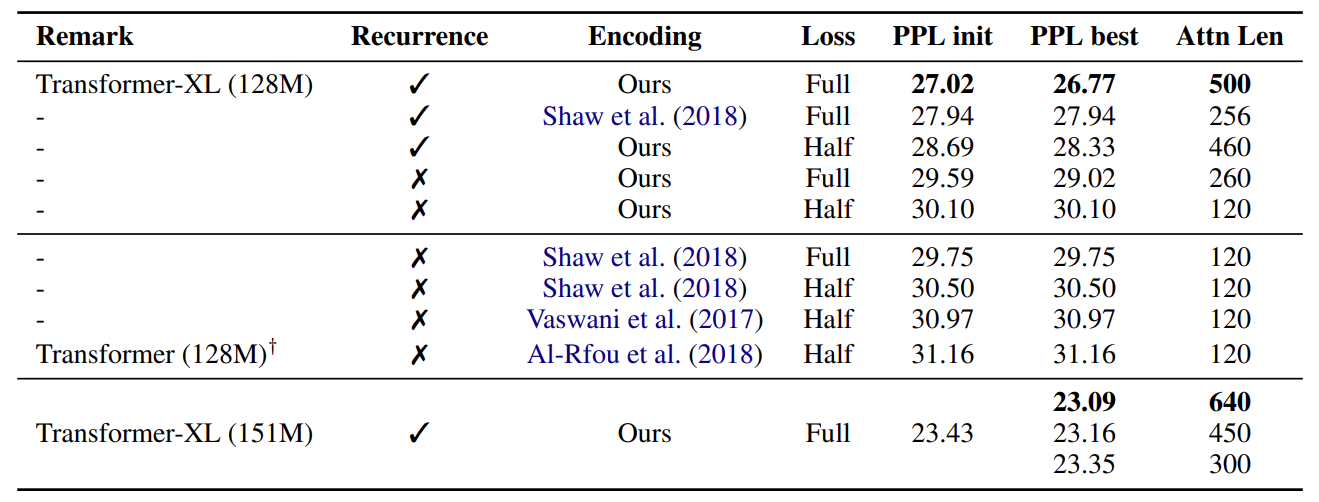
Compared to previous work, Transformer-XL has a quicker speed of training and inference. Recurrence scheme adds relative information between segments and relative positional encodings reduce the complexity of attention. Fixed length of segment and attention may not be a good choice.
PoolingFormer
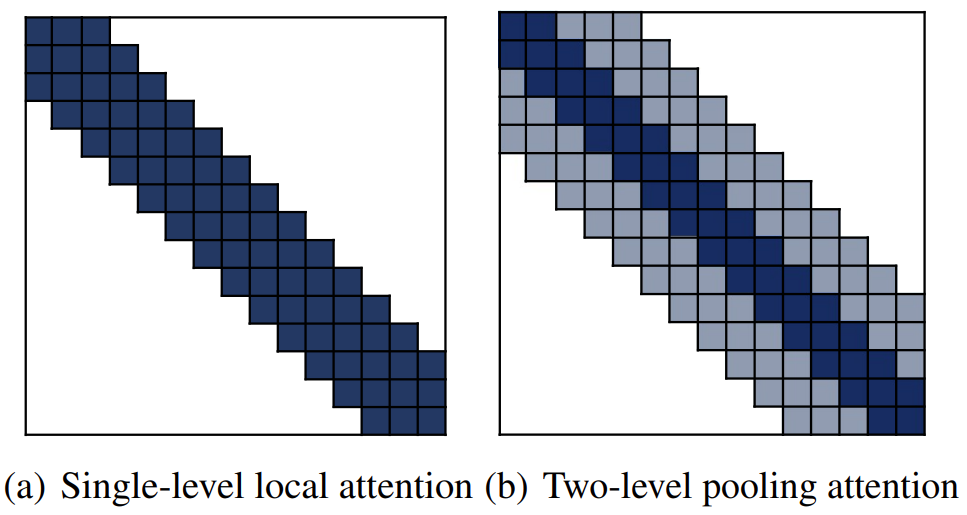
PoolingFormer consists of two level attention with $\text{O}(n)$ complexity. Its first level uses a smaller sliding window pattern to aggregate information from neighbors. Its second level employs a larger window to increase receptive fields with pooling attention to reduce both computational cost and memory consumption.
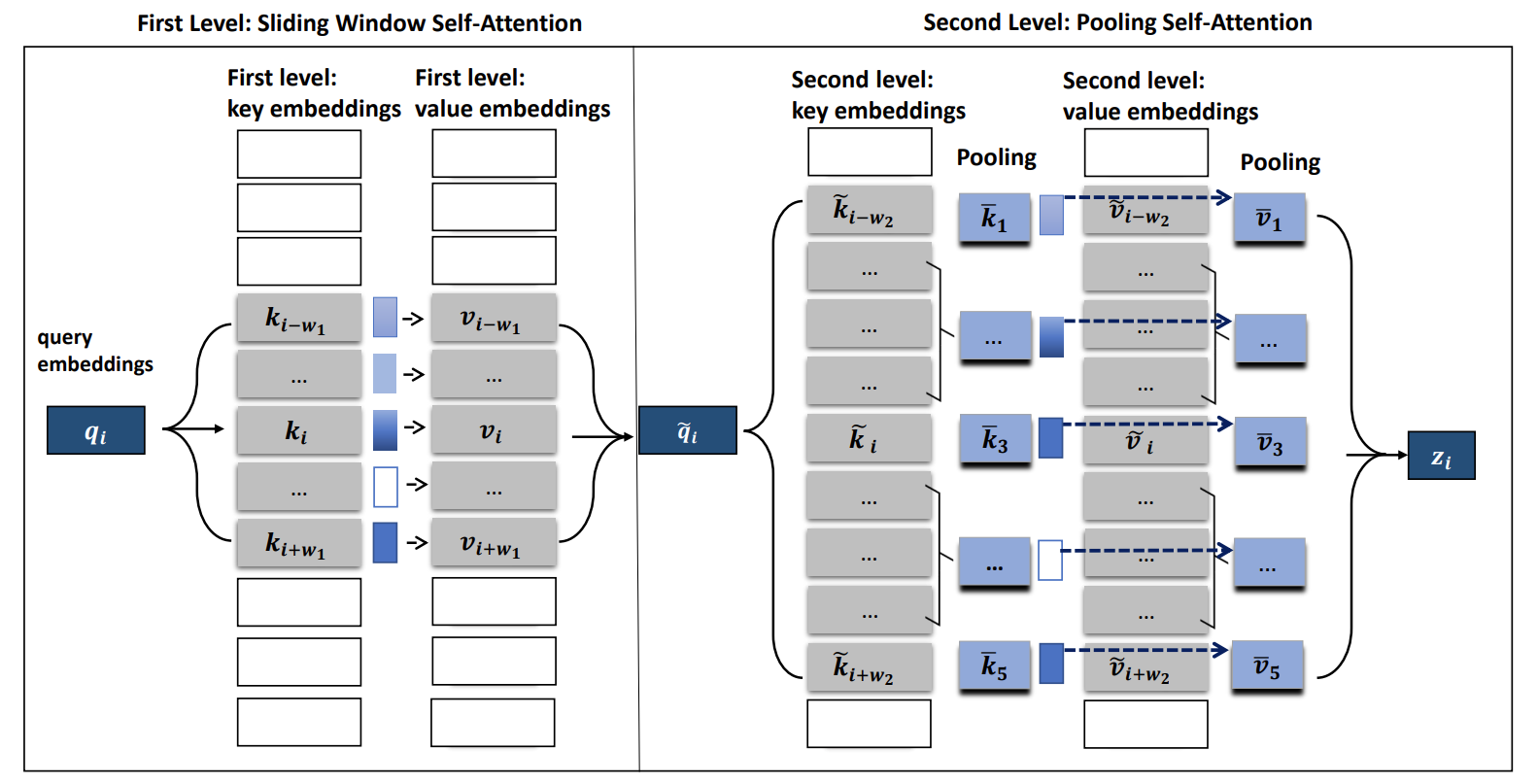
Pooling operation is to compress key and value matrices. In PoolingFormer, they use the lightweight dynamic convolution pooling (LDConv) as follows:
\[\text{LDConv}(v_1,v_2,\dots,v_k)=\sum_{i=1}^k\delta_i\cdot v_i\]Notice they just modifies some of layers of Transformer-based models. The window sizes of the first-level and second-level is normally set to 128 and 512. In addition, they adopt a residual connection between two levels.
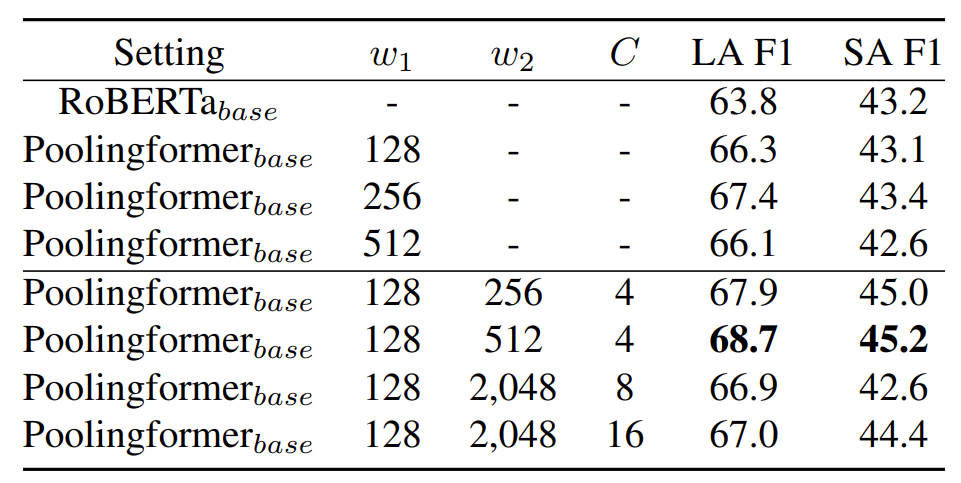
We conjecture that the reason for the poor performance of 512 windows size is that the self-attention mechanism is difficult to deal with remote token due to redundancy noise. We think that for every distant token, there may be too little useful information to compute attention. For the tokens that are very far away, we will discard them directly. In this way, tokens can pay more attention to key information and reduce computation and memory consumed.
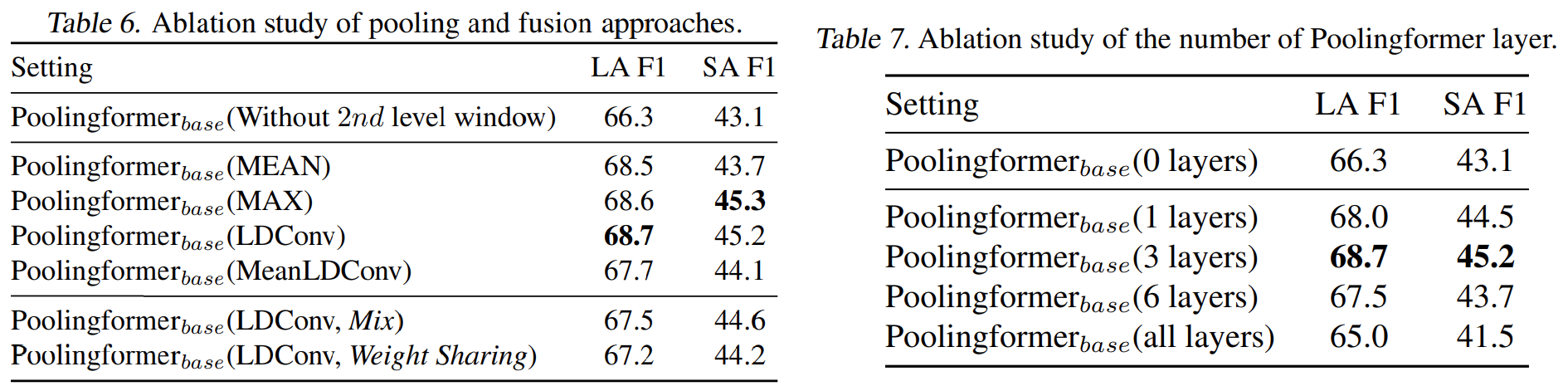
Table 6 compares different pooling operations. In Mix, the second-level pooling attention module is built upon the input embeddings instead of the output of the first-level attention, which illustrates the effectiveness of stacking two level attentions in Poolingformer. In Weight sharing, the first level and second level share the same attention matrices. Table 7 tells us which number of the PoolingFormer layers we should apply. The best results often happen when the number of Poolingformer layer is a quarter of the total number of layers.