Motivations
Modern computer vision neural networks are heavily parametrized. This high capacity models tend to overfit on small, or even medium sized datasets. Previous work about pre-training with label exists two problems:
- Domain shift: Having a large amount of images vastly compensates the domain discrepancy, while all the available information is controlled by the given dataset categorization bias.
- Supervision collapse: The network learns to focus on the mapping between images and the labels, discarding information that is relevant to other downstream tasks.
Thus, self-supervised pre-training methods are introduced to directly learn from data, such as the contrastive and joint embedding approaches. Such methods have a strong bias towards ImageNet data since the transformations have been hand-designed to perform well on the ImageNet benchmark. When applied on uncurated data, these methods degrade significantly and require larger datasets to obtain similar performance.
- How much does this pre-training technique rely on the number of pre-training samples?
- Is this technique robust to different distributions of training images?
SplitMask
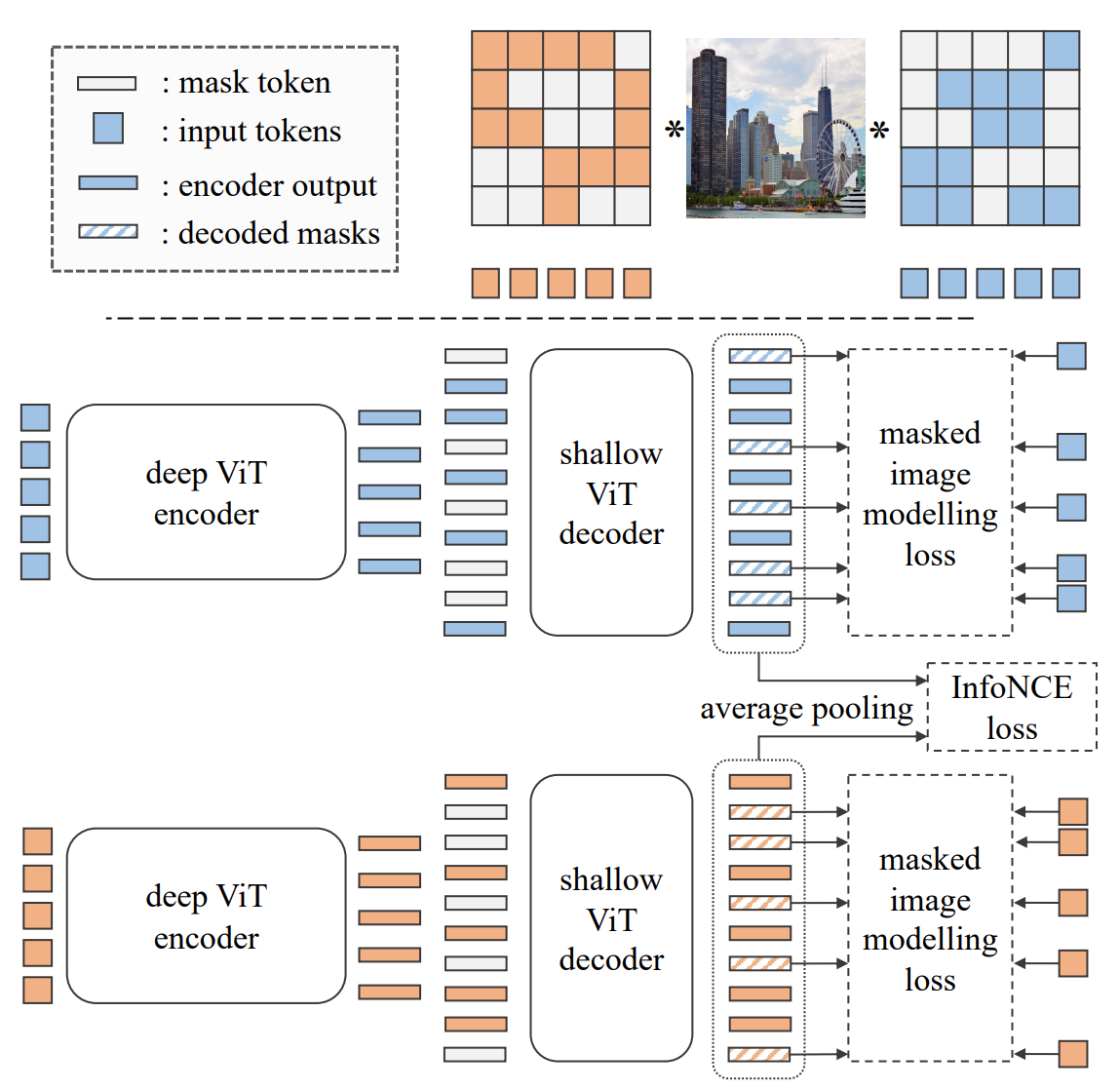
SplitMask takes two disjoint visible tokens of one masked image as input. It has an parallel asymmetric encoder-decoder architecture and get two global representation of one image by average pooling simultaneously. More details are as follows:
- Encoder: standard ViT encoder without masked tokens
- Decoder: shallow decoder (2-layers) than BEiT
- Reconstruction loss: cross entropy loss
- Negative samlpes: all the representations of the other images in one mini-batch
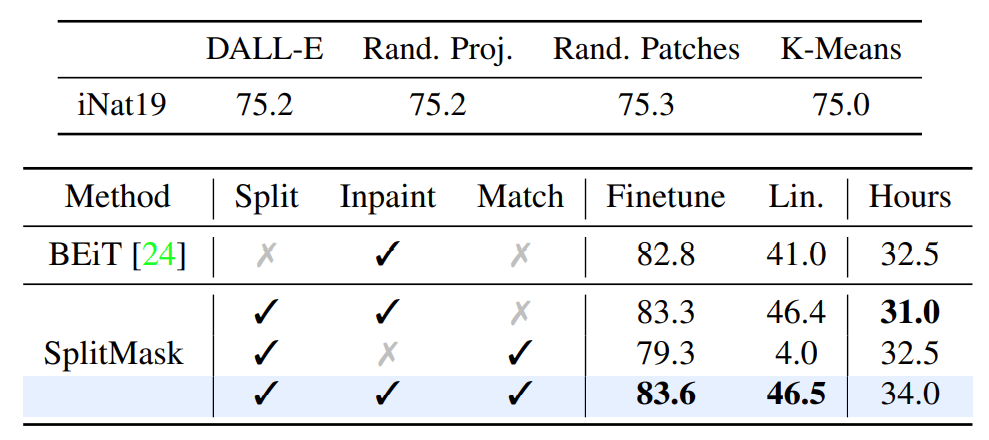
Notice that SplitMask takes tokens but not patches as input. It has a lightweight and more efficient tokenizers than BEiT. To tokenize an image, they associate each patch to the element of the vocabulary which has the highest cosine similarity with the patch in the pixel space. Figure 1 shows that the tokenizer could not be complicated. Figure 2 shows the effect of split mask and contrastive learning.
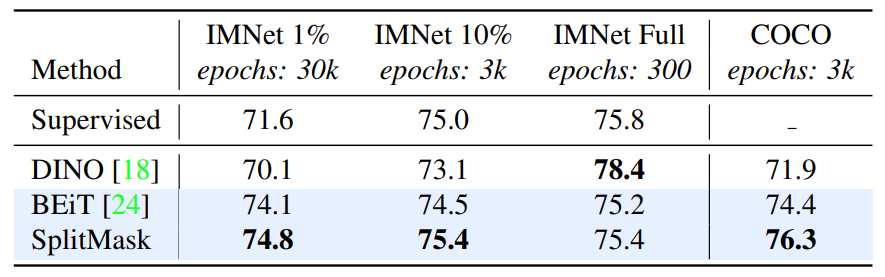
Figure 3 shows that the pre-training dataset size could be small. Notice DINO and BEiT has a drop on COCO. COCO images are not biased to be object-centric, while this joint embedding method was designed and developed using ImageNet as benchmark.

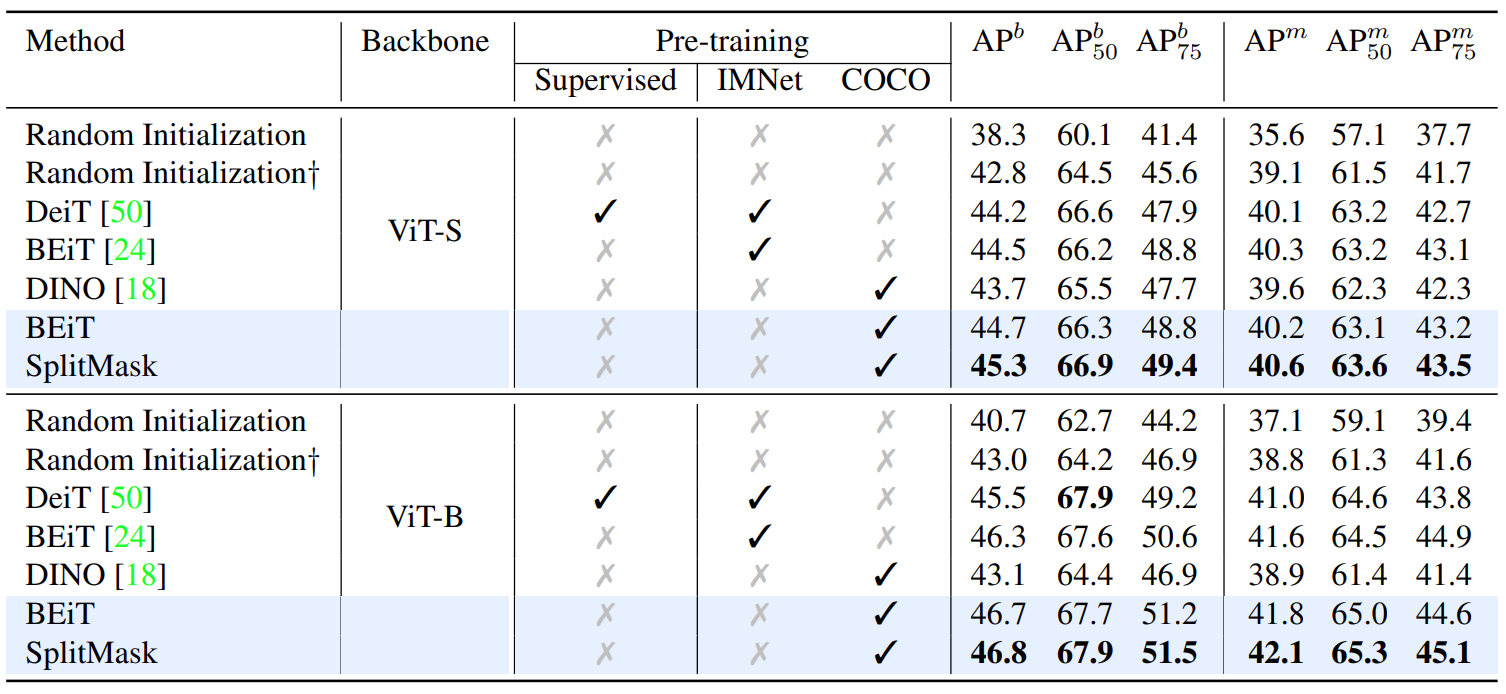
Figure 4 shows that the peak performance of the model is achieved using only 5% of the ImageNet samples, which means denoising autoencoders are highly sample efficient unsupervised learning methods. Training for long schedules on small datasets can achieve such strong performance as larger datasets. However, slight overfitting still occurs for very long schedules. Figure 5 shows the comparison on detection task.