Motivations
The context of a video is relatively static in a period of time. It depicts a global environment in which the action takes place. The motion of a video demonstrates dynamic changes which represents the local feature. A key challenge in self-supervised video representation learning is how to effectively capture motion information besides context bias.
Previous work always took raw RGB frames as input. There exist several problems we should solve:
- Which source of supervision is better?
- How to avoid the use of computationally expensive features such as optical flow, dense trajectories?
- How to avoid the model from learning low-level offsets?

Notice that video in compressed format such as H.264 and MPEG-4 roughly decouples the context and motion information in its I-frames and motion vectors. A compressed video stores only a few key frames and it reconstructs other frames based on motion vectors (i.e. pixel offsets) and residual errors from the key frames. All these modalities can be effectively extracted at more than 500 fps on CPU.
Context matching and Motion prediction
Based on compressed stream of a video, this paper proposes two auxiliary tasks in video representation learning:
- Context matching: It requires the model to discriminate between video clip and key frame features, which can learn global and coarse-grained representation.
- Motion predition: It requires the model to predict pointwise motion dynamics in a near future based on visual information of the current clip, which can get local and fine-grained representation.
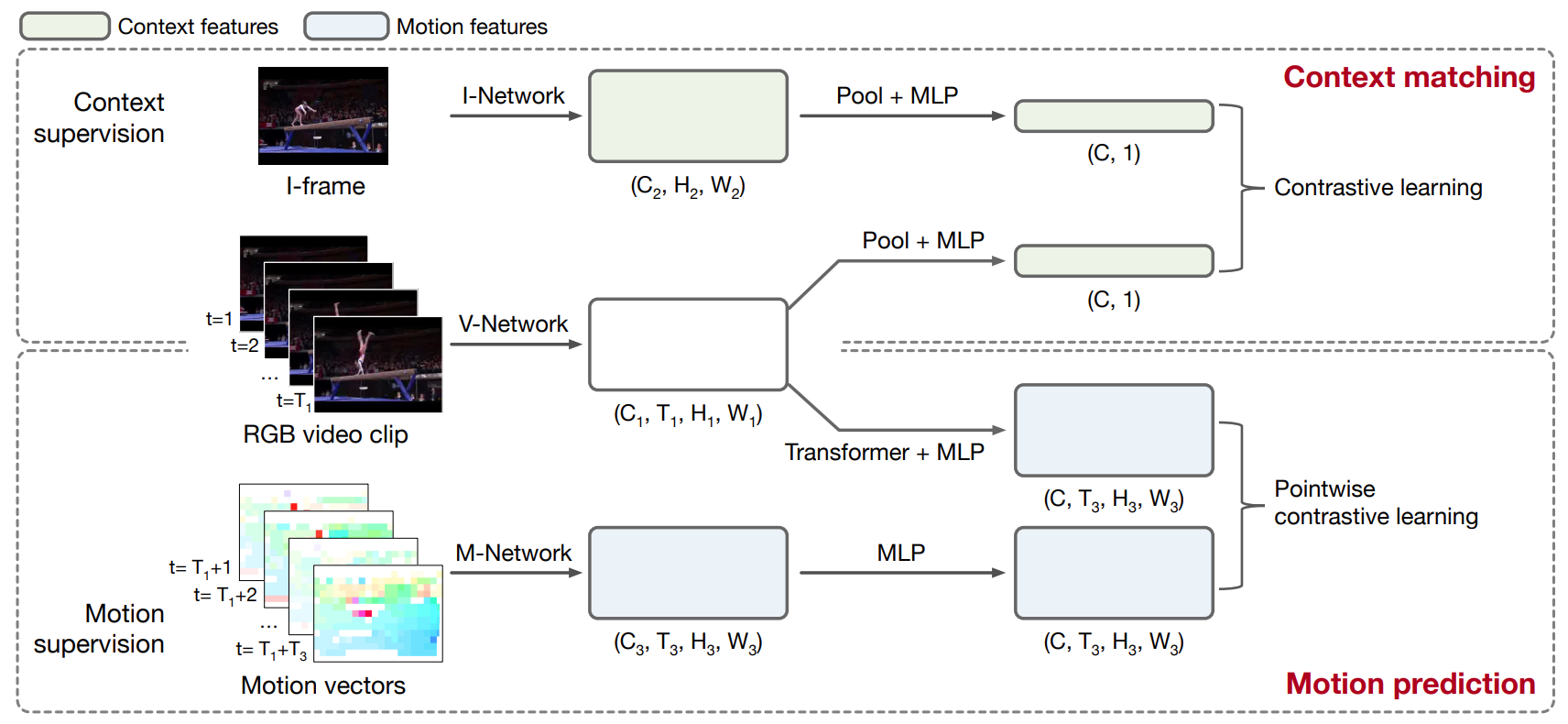
Both of them are optimized by contrastive learning. Context matching takes I-frames and clips from the same videos as positive pairs, while those from different videos as negative pairs. Instead of directly estimating the values of motion vectors, we first encode clips and motion vectors to predicted and real motion features at every spatial and temporal location. Only feature points corresponding to the same video and at the same spatial and temporal position are regarded as positive pairs.
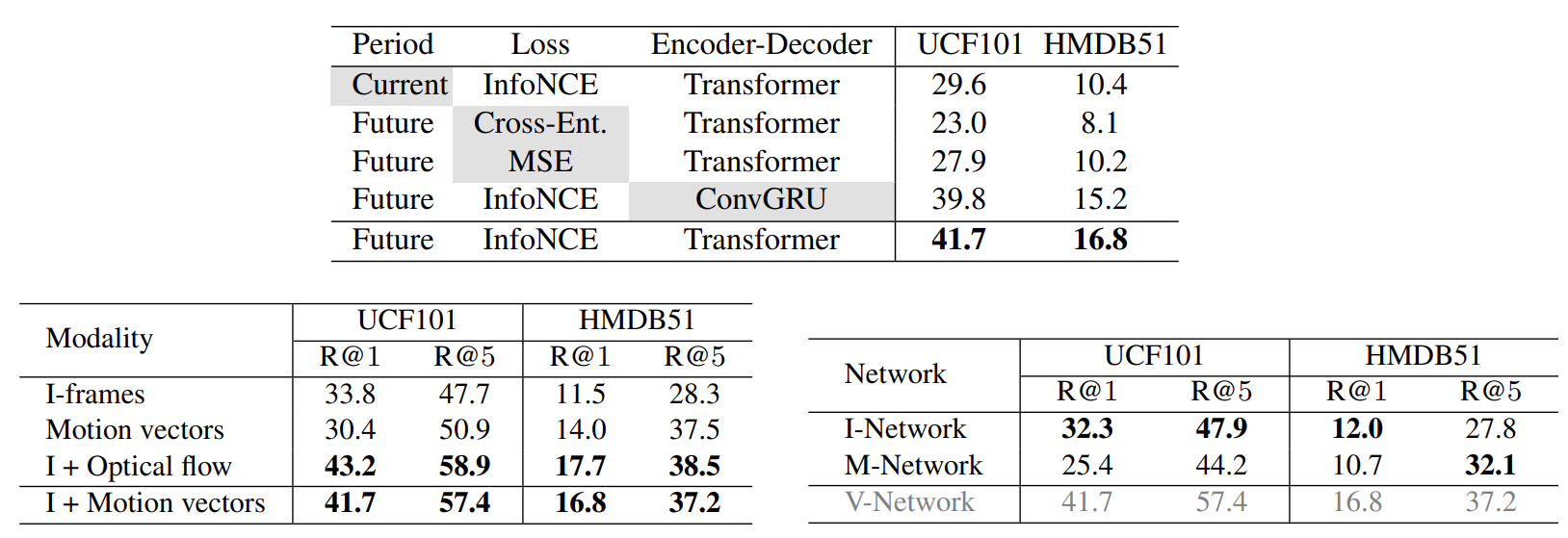
Figure 1 shows the importance of predicting future motion, InfoNCE and Transformer. Figure 2 shows the effect of different modalities. UCF101 contains more videos about static environment but HMDB51 is more concerned about dynamic motion. Figure 3 shows the performance of every aspect of the model.
Although applying contrastive learning on videos is not a novel appraoch. This paper first takes elements of compressed video as supervision and achieves good results, while they still neglect the effect of residual errors (supplementary information of motion vectors). We should go back to the data itself.