Motivations
What makes masked autoencoding different between vision and language?
- Architecture gap: It is hard to integrate tokens or positional embeddings into CNN, but ViT has addressed this problem.
- Information density: Languages are highly semantic and information-dense but images have heavy spatial redundancy, which means we can recover missing patches from neighboring patches with little high-level understanding of the data.
- Decoder design: In vision, the decoder reconstructs pixels, which means the output is of a lower semantic than common recognition tasks. While in languages, the decoder predicts missing words that contain rich semantic information.
Masked Autoencoders
Compared with traditional auxiliary tasks in vision, MAE introduces a strategy: masking a very high portion (75%) of random patches to induce the model to learn a holistic understanding. MAE masks random patches from the input image and reconstructs the missing patches in the pixel space.

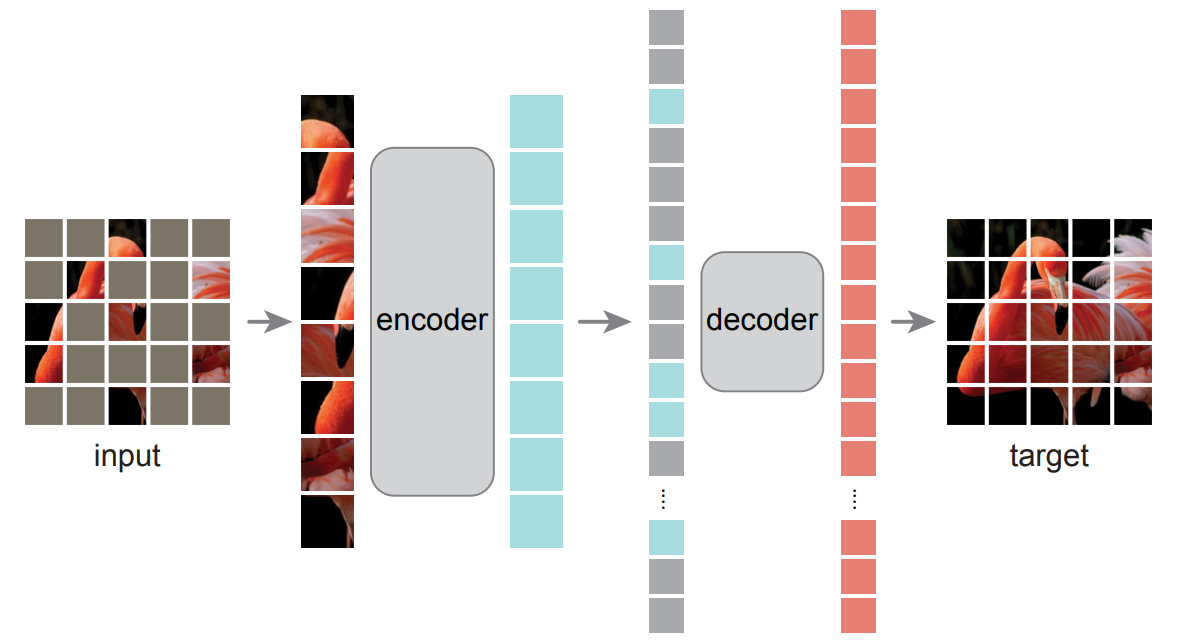
MAE has an asymmetric encoder-decoder architecture design as follows. Encoder operates only on the visible subset of patches (without mask tokens) and decoder is lightweight and reconstructs the input from the latent representation along with mask tokens.
1 | |
- MAE add positional embeddings to all tokens in this full set.
- Mask tokens would have no information about their location in the image.
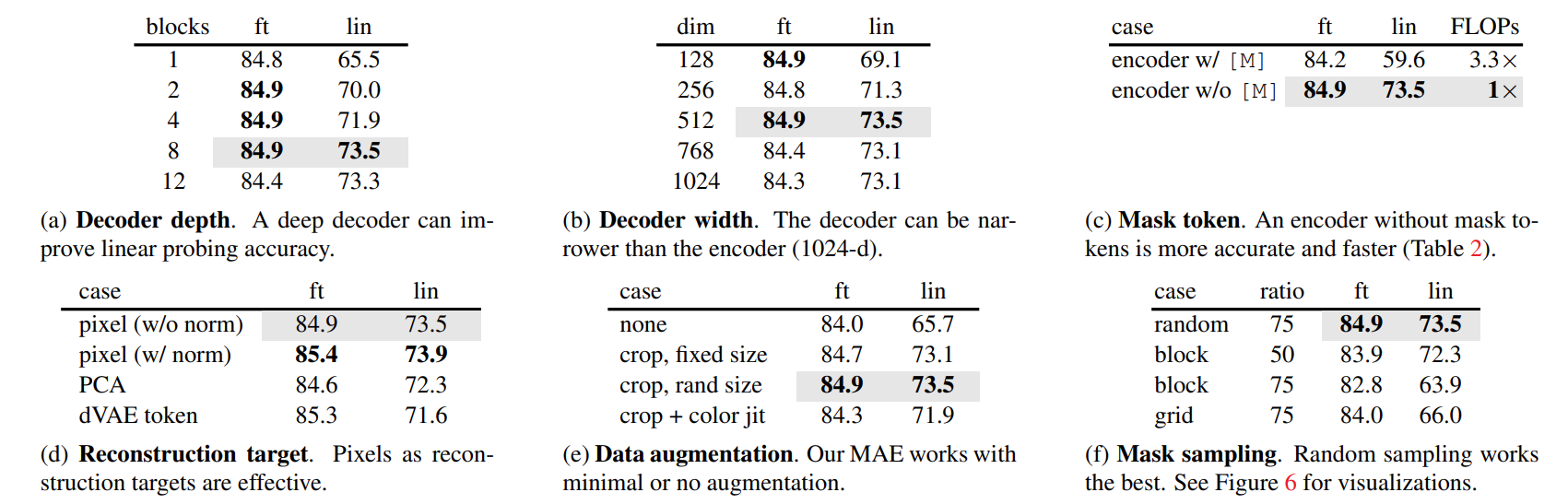
Figure (a) and (b) shows that decoder could be more flexible and lighter to reduce computation. Figure (c) demonstrates that removing mask token from the encoder is better. Encoder could always see real patches but not mask patches to exploit meaningful information. Figure (d) tells us that tokenization is not necessary for MAE. Figure (e) and (f) shows that MAE could work with minimal or no augmentation. On the contrary, contrastive learning methods in vision require heavy data augmentation up to now. In MAE, the masks are different for each iteration and so they generate new training samples regardless of data augmentation. The key insights of MAE can be concluded as follows:
- High ratio of mask usage
- Randomly mask patches for each iteration
- Remove mask token from the encoder
- Lightweight decoder which reconstructs image on pixel level